Mybatis 中的一级缓存与二级缓存_mybatis一级缓存和二级缓存-程序员宅基地
一,Mybatis中为什么要有缓存
缓存的意义是将用户经常查询的数据放入缓存(内存)中去,用户去查询数据的时候就不需要从磁盘(关系型数据库)中查询,直接从缓存中查询,从而提高了查询效率,解决了高并发中系统的性能问题。Mybatis中提供一级缓存与二级缓存。

Mybatis的一级缓存是一个SqlSession级别的缓存,只能访问自己的一级缓存数据,而二级缓存是Mapper级别的缓存,是跨SqlSession的,不同的SqlSession是可以共享缓存数据的。
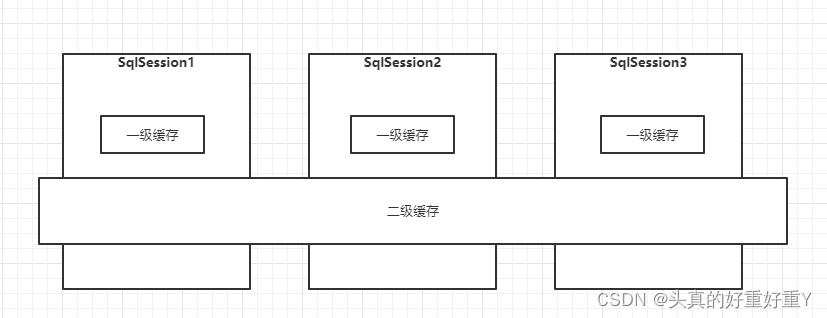
二,一级缓存
Mybatis 一级缓存原理:
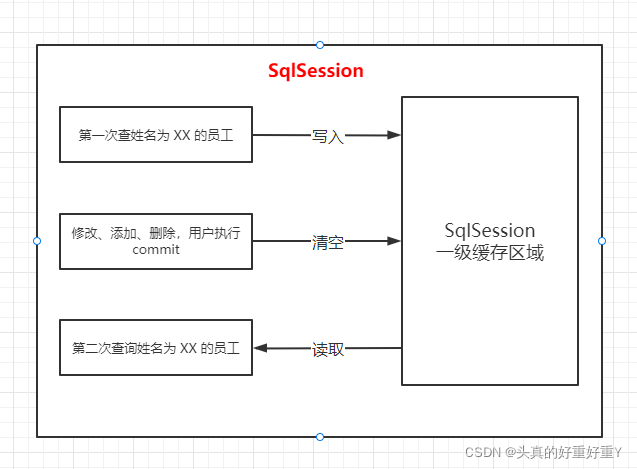
第一次发出查询请求,sql 查询的结果写入SqlSession的一级缓存当中,缓存使用的数据结构是一个map<key, value>
- key : hashcode + sql + sql输入参数 + 输出参数 (sql的唯一标识)
- value : 用户信息
同一个SqlSession再次发出相同的sql,就会从缓存中读取而不走数据库,如果两次操作之间出现commit(修改、输出、添加)操作,那么本SqlSession中一级缓存区域全部清空,下次再去缓存中查不到所以要从数据库中查询,从数据库再写入一级缓存。
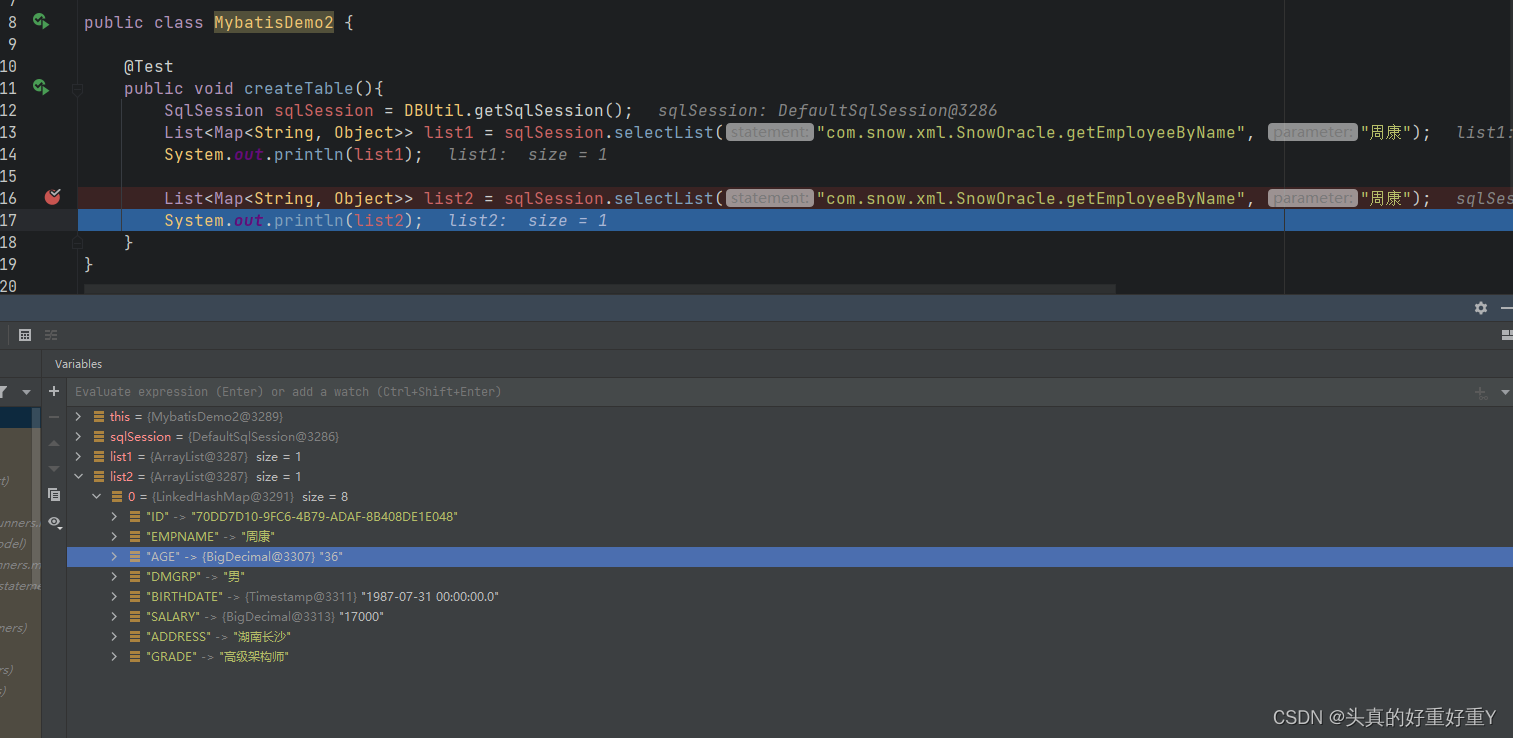
@Test
public void createTable(){
SqlSession sqlSession = DBUtil.getSqlSession();
List<Map<String, Object>> list1 = sqlSession.selectList("com.snow.xml.SnowOracle.getEmployeeByName", "周康");
System.out.println(list);
List<Map<String, Object>> list2 = sqlSession.selectList("com.snow.xml.SnowOracle.getEmployeeByName", "周康");
System.out.println(list2);
}
在数据库中有一张Employee表,里面有一条数据,通过selectList的方法查询,结果如下[{ID=70DD7D10-9FC6-4B79-ADAF-8B408DE1E048, EMPNAME=周康, AGE=36, DMGRP=男, BIRTHDATE=1987-07-31 00:00:00.0, SALARY=17000, ADDRESS=湖南长沙, GRADE=高级架构师}]
此时,手动修改数据库该人的年龄,手动修改为35,然后保存
此时,在运行代码,查看list2的值,两次结果一致,都是36 并非 35,说明第二次相同的查询走的是SqlSession中的一级缓存。
Mybatis 中一级缓存需要注意的点 :
Mybatis中一级缓存是默认开启的,不需要手动配置。Mybatis和Spring整合后进行mapper代理开发后,不支持一级缓存。Mybatis和Spring整合,Spring按照mapper的模板去生成mapper代理对象,模板中在最后会统一关闭SqlSession。
三、二级缓存
Mybatis二级缓存原理:
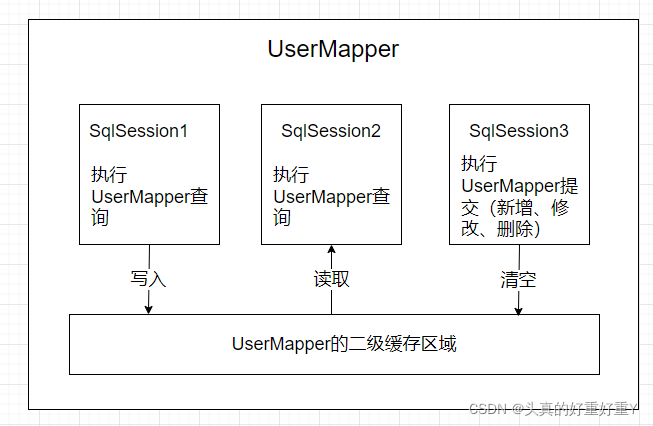
二级缓存的范围是mapper级别(mapper同一个命名空间),mapper以命名空间为单位创建缓存数据结构,结构是map<key, value>。每次查询前看是否开启了二级缓存,如果开启则从二级缓存的数据结构中取缓存数据,如果二级缓存中没有取到,再从一级缓存中取,如果一级缓存也没有,那就从数据库中查询。
- 二级缓存配置
需要在Mybatis的配置文件中<settings>标签中配置二级缓存:
<settings>
<setting name="cacheEnabled" value="true"/> <!--Mybatis的二级缓存配置-->
</settings>
Mybatis的二级缓存的范围是mapper级别的,因此我们mapper如果想要使用二级缓存,还需要在对应的映射文件中配置<cache>标签
<mapper namespace="com.snow.xml.SnowOracle">
<cache></cache> <!--Mybatis的二级缓存配置-->
</mapper>
测试:
@Test
public void test(){
SqlSession sqlSession1 = DBUtil.getSqlSession();
List<Map<String, Object>> list1 = sqlSession1.selectList("getEmployeeByName", "周康");
System.out.println("list1=" + list1);
sqlSession1.commit();
sqlSession1.close();
DBUtil.closeSqlsession();
SqlSession sqlSession2 = DBUtil.getSqlSession();
List<Map<String, Object>> list2 = sqlSession2.selectList("getEmployeeByName", "周康");
System.out.println("list2=" + list2);
sqlSession2.commit();
sqlSession2.close();
}
在SqlSession2 创建处打断点,观看此时输出:list1=[{ID=70DD7D10-9FC6-4B79-ADAF-8B408DE1E048, EMPNAME=周康, AGE=35, DMGRP=男, BIRTHDATE=1987-07-31 00:00:00.0, SALARY=17000, ADDRESS=湖南长沙, GRADE=高级架构师}]
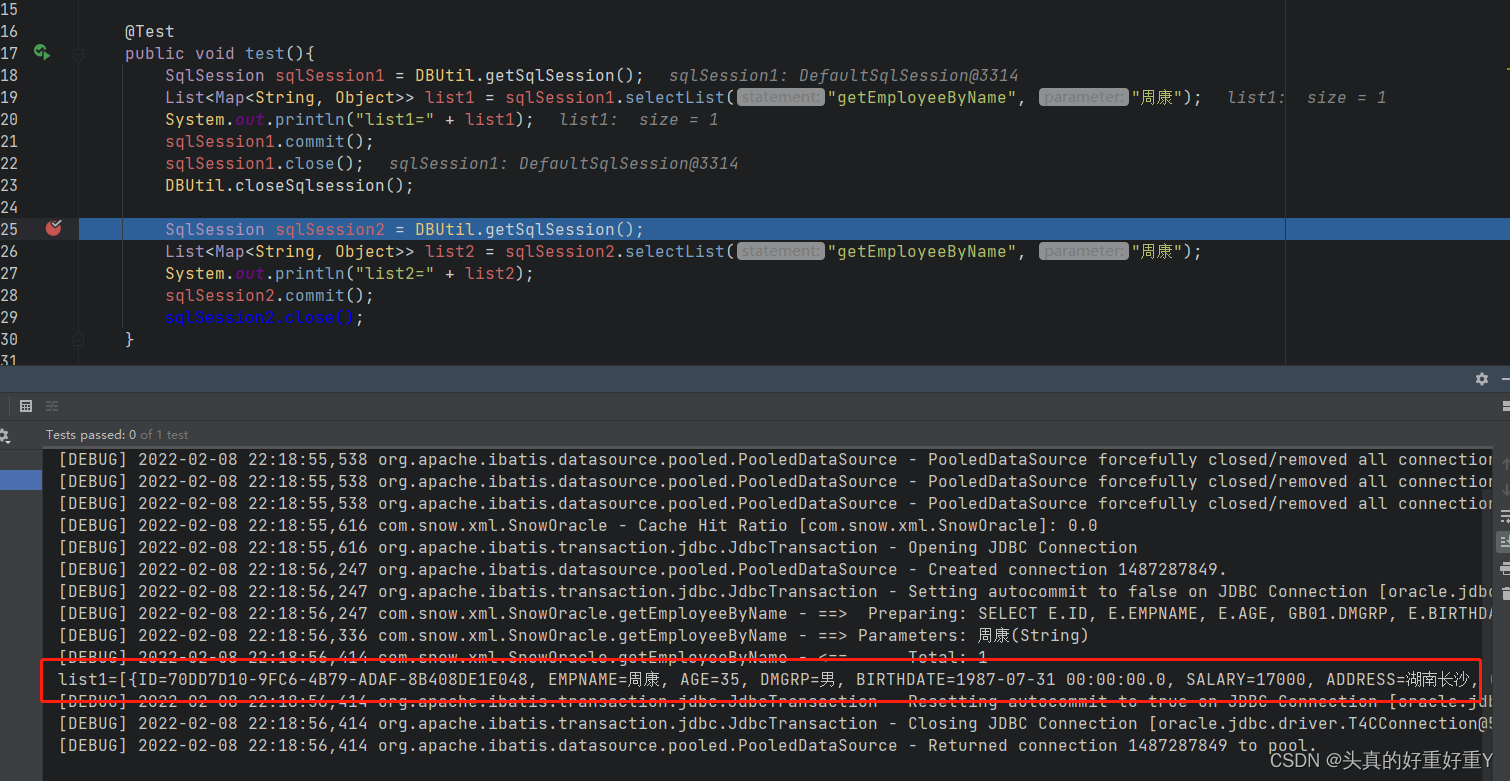
此时去修改数据库中周康此人的年龄,改为37提交,代码继续往下执行,会看到SqlSession2 与SqlSession1 是两个不同的SqlSession,观看此时输出:list2=[{ID=70DD7D10-9FC6-4B79-ADAF-8B408DE1E048, EMPNAME=周康, AGE=35, DMGRP=男, BIRTHDATE=1987-07-31 00:00:00.0, SALARY=17000, ADDRESS=湖南长沙, GRADE=高级架构师}]
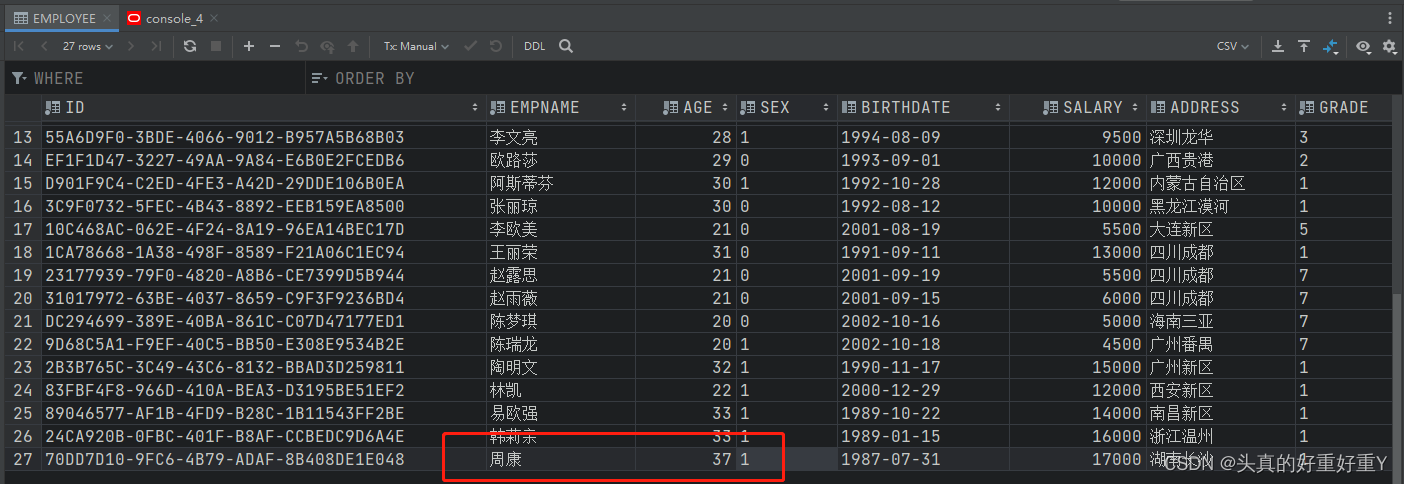
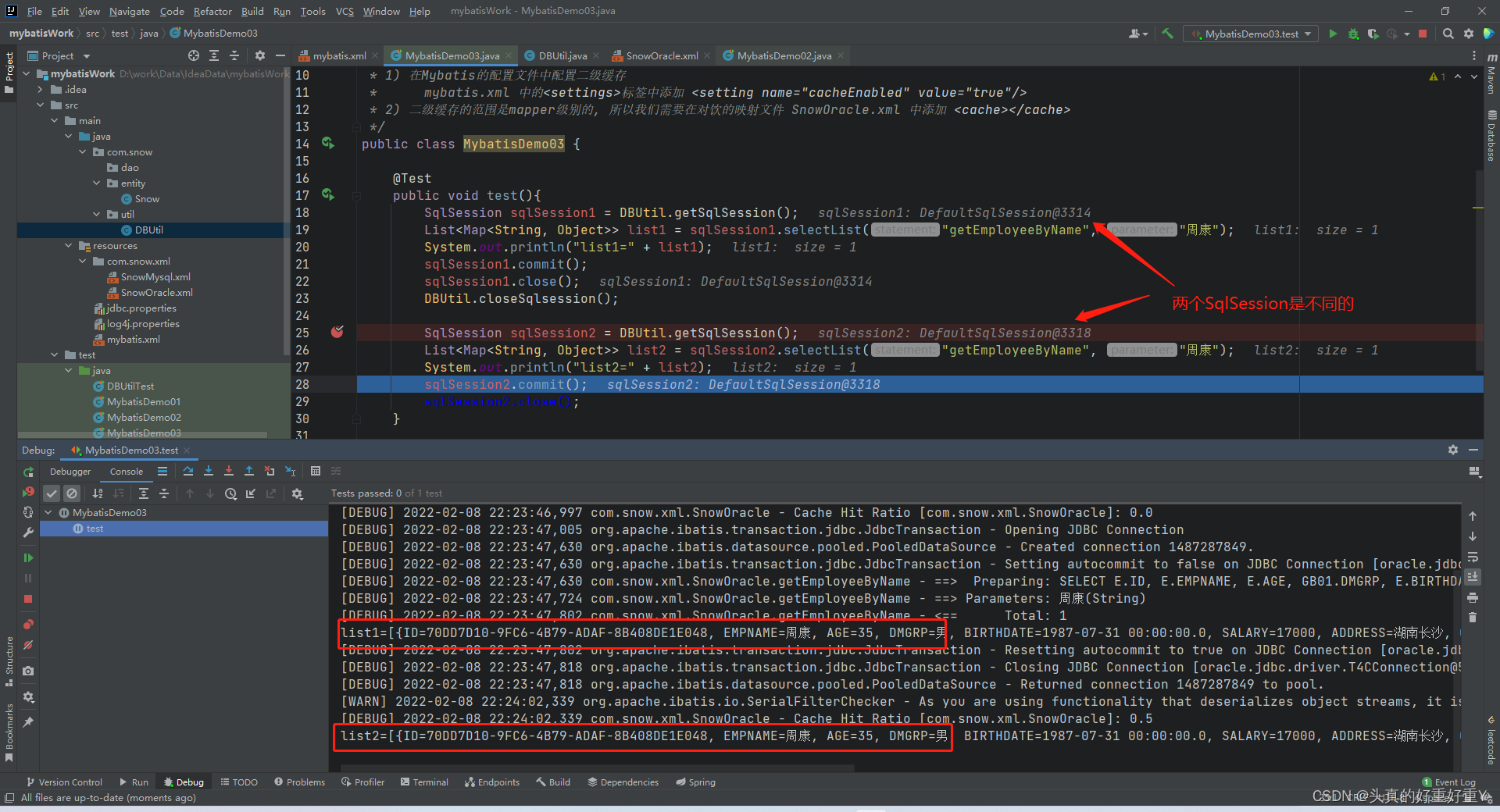
两次结果一致,均为35岁,说明SqlSession2 的查询没有走数据库,而是用了Mybatis的二级缓存,从里面拿到的数据,虽然是两个不同的SqlSession,但是二级缓存是mapper级别的,SqlSession1 只执行了查询操作没有增改删,所以不会清空二级缓存中的数据。
此处如果关闭了二级缓存的配置,查询出来的结果会是实时的,因为一级缓存默认开启,一级缓存的作用是SqlSession级别的,不同的SqlSession缓存数据不共享。这里就不演示一级缓存效果了。
- 禁用二级缓存
有些情况下,我们需要打开二级缓存的配置,但是某个sql语句的查询变化频率较高,则需要针对该sql禁用二级缓存。在xml中statement中设置useCache=false 则可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认是true(使用二级缓存)
<select id="getEmployeeByName" parameterType="string" resultType="java.util.LinkedHashMap" useCache="false">
SELECT E.ID, E.EMPNAME, E.AGE, GB01.DMGRP, E.BIRTHDATE, E.SALARY, E.ADDRESS, GB02.DMGRP AS GRADE
FROM EMPLOYEE E LEFT JOIN GB01 ON E.SEX = GB01.ID LEFT JOIN GB02 ON E.GRADE = GB02.ID
WHERE E.EMPNAME = #{name}
</select>
测试:
操作与上面一样,SqlSession2处打断点,更改数据库中该人的年龄,查看两次输出结果。

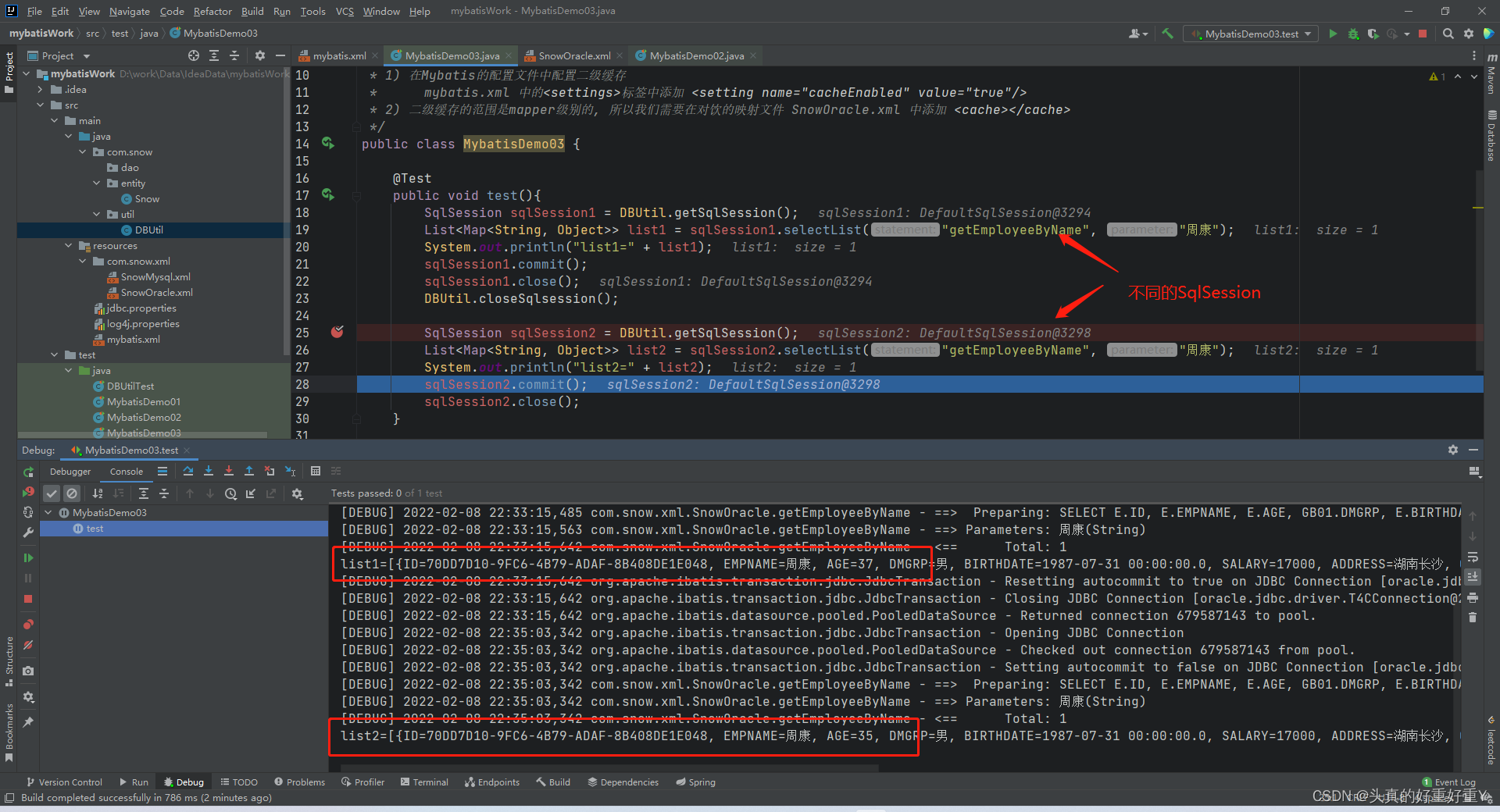
list1=[{ID=70DD7D10-9FC6-4B79-ADAF-8B408DE1E048, EMPNAME=周康, AGE=37, DMGRP=男, BIRTHDATE=1987-07-31 00:00:00.0, SALARY=17000, ADDRESS=湖南长沙, GRADE=高级架构师}]
list2=[{ID=70DD7D10-9FC6-4B79-ADAF-8B408DE1E048, EMPNAME=周康, AGE=35, DMGRP=男, BIRTHDATE=1987-07-31 00:00:00.0, SALARY=17000, ADDRESS=湖南长沙, GRADE=高级架构师}]
可以看到操作虽然与第一次一样,可结果却变了,虽然二级缓存中有周康该人的信息,但是SqlSession2 还是从数据库中查询到了此人最新的数据,因为我们禁用了二级缓存。useCache=false
- 增删改的二级缓存
二级缓存其实大部分都是为查询服务的,对于它们而言,如果我们缓存的数据不是最新的那么就会读到脏数据了。增删改之后之所以二级缓存会被清空是因为它们有一个默认的flushCache=true,默认在sql结束后刷新二级缓存,可以通过修改配置值达到不刷新缓存的目的(不建议使用)。
<update id="updateAgeByName" parameterType="string" flushCache="false">
UPDATE EMPLOYEE SET AGE = '40' WHERE EMPNAME = #{EMPNAME}
</update>
四、了解Mybatis缓存的一些参数
mybatis 的cache 参数只适用于mybatis 维护缓存。
flushInterval : 刷新间隔,可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式时间段,默认情况是不设置,也就是没有刷新间隔,缓存仅仅在调用语句时刷新。
size : 引用数目,可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目默认值为1024。
readOnly : 只读属性,可被设置为true or false,只读的缓存会给所有调用者返回缓存对象的相同实例,因此这些对象不能被修改,这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这样会导致效率慢一些,但是安全,默认值为false。
<cache eviction="FIFO" flushInterval="6000" size="512" readOnly="true" />
这样的二级缓存配置,创建了一个FIFO的缓存,并且每隔60秒刷新,存数结果对象或列表的512个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。
默认的回收策略有(默认为LRU):
- LRU:最近最少使用的,移除最长时间不被使用的对象。
- FIFO:先进先出,俺对象进入缓存的顺序来移除它们。
- SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象。
- WEAK:弱引用,更积极地移除给予垃圾回收器状态和弱引用规则的对象。
智能推荐
NOI题库答案 (1.7 字符串基础)(1-20)-程序员宅基地
文章浏览阅读1.9w次,点赞20次,收藏64次。 01:统计数字字符个数描述输入一行字符,统计出其中数字字符的个数。输入一行字符串,总长度不超过255。输出输出为1行,输出字符串里面数字字符的个数。样例输入Peking University is set up at 1898.样例输出4#include<bits/stdc++.h>using namespace std;in...
传授人生经验(预处理)_轩神与奇牛是师徒,也是k友,经常打2k,可奇牛老是不故意放水让轩神输,于是轩神决定-程序员宅基地
文章浏览阅读769次。Description轩神与奇牛是师徒,也是K友,经常打2K,可奇牛老是不故意放水让轩神输,于是轩神决定给奇 牛传授点人生经验以作补偿。 轩神拿出其珍藏多年的人生经验打造了n个经验球并连成一串,每一 个球里都含着一定量的人生经验。好玩的是,你打破一个球,你没法获得里面的人生经验,而只 能获得打破的那个球两边球的经验绝对值差。 假设轩神造了5个球,按顺序为 1 2 3 4 5 那么打破_轩神与奇牛是师徒,也是k友,经常打2k,可奇牛老是不故意放水让轩神输,于是轩神决定
以Vivado工具为例了解FPGA综合-程序员宅基地
文章浏览阅读4.3k次,点赞11次,收藏88次。在设计过程中,各个阶段的生成的文件都是.dcp,Vivado使用的是通用的模型贯穿在设计。_fpga综合
在Ubuntu上安装更轻量且响应更快的XFCE桌面环境_ubuntu xfce-程序员宅基地
文章浏览阅读3k次。通过安装XFCE桌面环境,你可以在Ubuntu上获得更轻量级和响应更快的桌面体验。在本文中,我们介绍了安装XFCE的步骤,包括更新系统、安装XFCE、配置默认的显示管理器和选择XFCE桌面环境。如果你在Ubuntu上寻求一种更轻便的桌面环境,那么安装XFCE可能是一个不错的选择。安装XFCE后,你需要将默认的显示管理器设置为LightDM,以便在登录时使用XFCE桌面环境。根据自己的需要进行调整,并享受你全新的XFCE桌面环境。现在,你可以享受在Ubuntu上使用XFCE的轻便和快速的桌面体验了!_ubuntu xfce
键值对集合-程序员宅基地
文章浏览阅读3.4k次。键值对集合Set集合Set集合是什么Set对象是值的集合,可以按照插入的顺序迭代它的元素。Set集合中的元素只会出现一次,即 Set集合中的元素是唯一的。const set = new Set([1,2,3,4,5]);NaN和 undefined都可以被存储在Set集合中,NaN之间被视为相同的值。const set = new Set([NaN,NaN]);console.log(set);// Set { NaN }对象被存储在Set集合中时,两个对象总是不相等的。const s_键值对集合
蓝桥杯 海盗比酒量-程序员宅基地
文章浏览阅读445次。海盗比酒量有一群海盗(不多于20人),在船上比拼酒量。过程如下:打开一瓶酒,所有在场的人平分喝下,有几个人倒下了。再打开一瓶酒平分,又有倒下的,再次重复...... 直到开了第4瓶酒,坐着的已经所剩无几,海盗船长也在其中。当第4瓶酒平分喝下后,大家都倒下了。等船长醒来,发现海盗船搁浅了。他在航海日志中写到:“......昨天,我正好喝了一瓶.......奉劝大家,开船不喝酒,喝酒别开船.........
随便推点
人工智能之华为云5G基站有AI,智能处理流量“潮汐”-程序员宅基地
文章浏览阅读1.9k次,点赞3次,收藏16次。一、5G 基站能否智能“省电”?① 能耗和能效随着中国 5G 基站部署规模的扩大,5G 基站能耗惊人的说法甚嚣尘上,众口铄金,5G 基站似乎坐实“电老虎”的尴尬地位。如下是一张某运营商的内部流出照片,从中可以看出,5G AAU 和 4G RRU 的满载功耗相差极为悬殊,不得不承认 5G 的能耗确实远高于 4G:在移动的节能技术白皮书中,也明确地写着:“2019 年初 5G 基站功耗约为 4G 基站的 3~4 倍,高功耗是运营商大规模部署 5G 的棘手问题”:联通也在其白皮书中写道:“5
flyme8.1.5.0A精简内置软件包_flyme8精简-程序员宅基地
文章浏览阅读6k次。flyme8.1.5.0A系统精简内置软件包提示:精简系统有风险 在精简之前先备份资料 sdcard目录放置官网刷机包以备重新刷机在pc端用adb命令精简手机系统手机端打开usb调试模式 设置 ———关于手机————版本号 点击6~8次进入开发者模式设置————辅助功能————开发者选项————开启开发者选项 打开usb调试platform-tools下载地址https://developer.android.com/studio/releases/platfor_flyme8精简
解决盲注编码问题-程序员宅基地
文章浏览阅读366次。Traceback (most recent call last): File "E:/Pycharm Project/CTF/xman-ctf��¼.py", line 56, in <module> if accesss(urllib.unquote(sub_tables(i, w))): File "E:/Pycharm Project/CTF/xman-ctf��..._codefever盲注
你管这破玩意儿叫高可用-程序员宅基地
文章浏览阅读2.1k次,点赞4次,收藏33次。大家好,我是坤哥今天我们来聊一下互联网三高(高并发、高性能、高可用)中的高可用,看完本文相信能解开你关于高可用设计的大部分困惑前言高可用(High availability,即 HA)的主..._码海 架构 分层
线性插值和二次插值_插值参数模型的线性回归连接和重要主题-程序员宅基地
文章浏览阅读5.5k次。线性插值和二次插值The model may turn out to be far too complex if we continuously keep adding more variables. 如果我们不断增加更多的变量,该模型可能会变得过于复杂。 Will fail to simplify as it is memorizing the training data. 记住训练数据将无法..._回归插值必须是线性
nested exception is org.springframework.jdbc.BadSqlGram 问题-程序员宅基地
文章浏览阅读7.3k次。type Exception reportmessage Request processing failed; nested exception is org.springframework.jdbc.BadSqlGrammarException:description The server encountered an internal error that prevented it f..._nested exception is org.springframework.jdbc.badsqlgrammarexception: