Flink 实时写入数据到 ElasticSearch 性能调优-程序员宅基地
背景说明
线上业务反应使用 Flink 消费上游 kafka topic 里的轨迹数据出现 backpressure,数据积压严重。单次 bulk 的写入量为:3000/50mb/30s,并行度为 48。针对该问题,为了避免影响线上业务申请了一个与线上集群配置相同的 ES 集群。本着复现问题进行优化就能解决的思路进行调优测试。
测试环境
Elasticsearch 2.3.3
Flink 1.6.3
flink-connector-elasticsearch 2_2.11
八台 SSD,56 核 :3 主 5 从
Rally 分布式压测 ES 集群
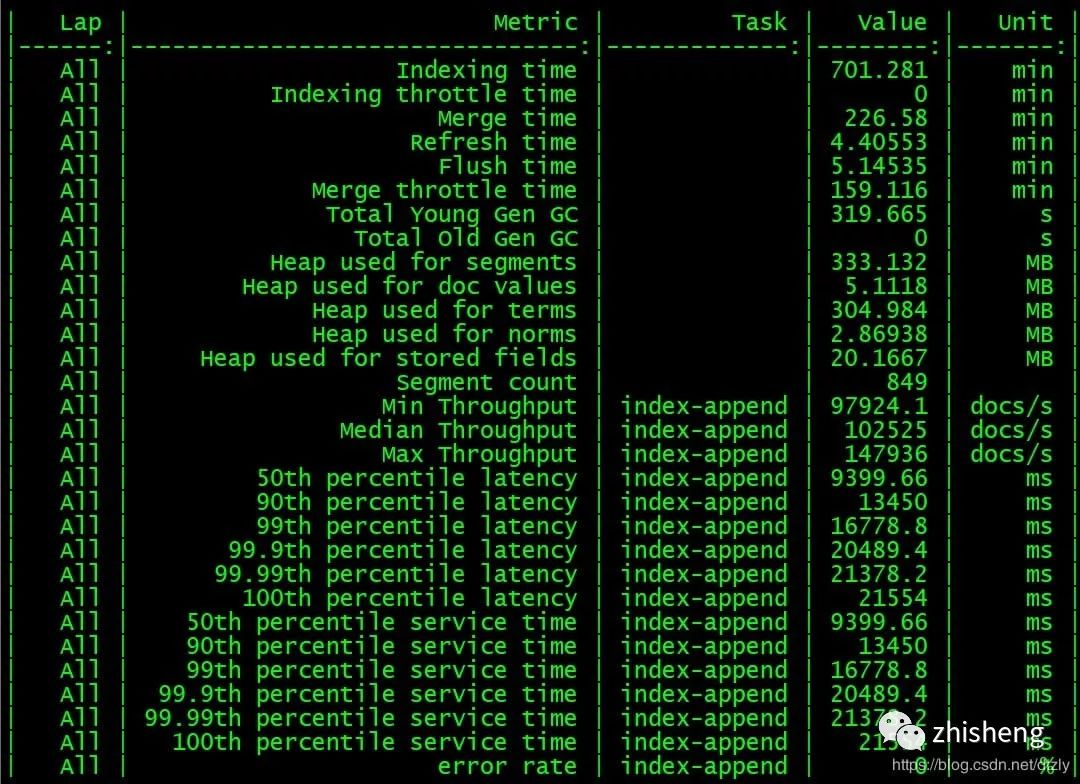
从压测结果来看,集群层面的平均写入性能大概在每秒 10 w+ 的 doc。
Flink 写入测试
配置文件
1config.put("cluster.name", ConfigUtil.getString(ES_CLUSTER_NAME, "flinktest"));
2config.put("bulk.flush.max.actions", ConfigUtil.getString(ES_BULK_FLUSH_MAX_ACTIONS, "3000"));
3config.put("bulk.flush.max.size.mb", ConfigUtil.getString(ES_BULK_FLUSH_MAX_SIZE_MB, "50"));
4config.put("bulk.flush.interval.ms", ConfigUtil.getString(ES_BULK_FLUSH_INTERVAL, "3000"));执行代码片段
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
initEnv(env);
Properties properties = ConfigUtil.getProperties(CONFIG_FILE_PATH);
//从kafka中获取轨迹数据
FlinkKafkaConsumer010<String> flinkKafkaConsumer010 =
new FlinkKafkaConsumer010<>(properties.getProperty("topic.name"), new SimpleStringSchema(), properties);
//从checkpoint最新处消费
flinkKafkaConsumer010.setStartFromLatest();
DataStreamSource<String> streamSource = env.addSource(flinkKafkaConsumer010);
10//Sink2ES
streamSource.map(s -> JSONObject.parseObject(s, Trajectory.class))
.addSink(EsSinkFactory.createSinkFunction(new TrajectoryDetailEsSinkFunction())).name("esSink");
env.execute("flinktest");运行时配置
任务容器数为 24 个 container,一共 48 个并发。savepoint 为 15 分钟:
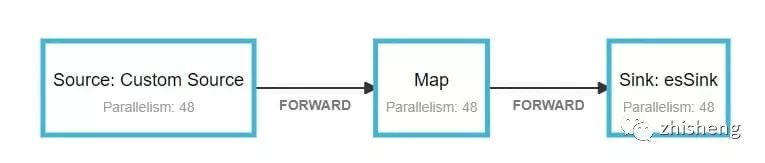
运行现象
(1)source 和 Map 算子均出现较高的反压
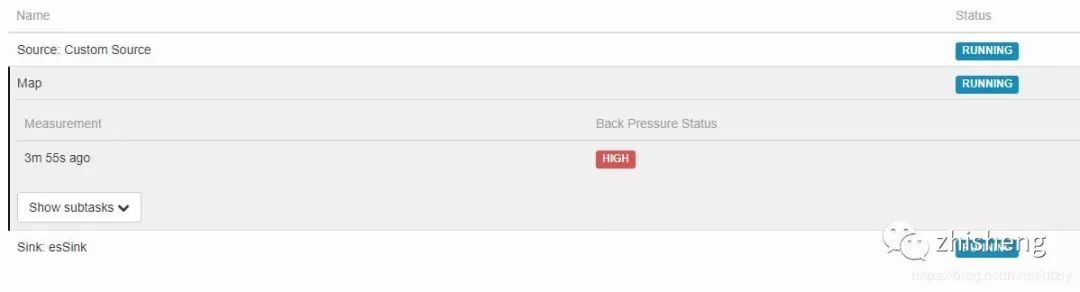
(2)ES 集群层面,目标索引写入速度写入陡降
平均 QPS 为:12 k 左右。
(3)对比取消 sink 算子后的 QPS
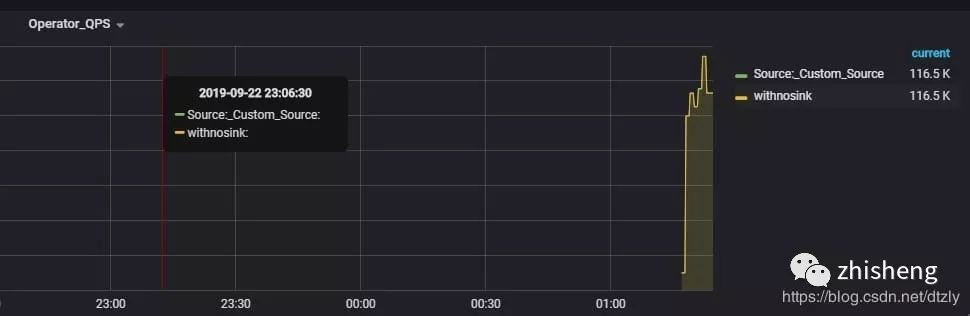
平均QPS为:116 k 左右。
有无sink参照实验的结论:
取消 sink 2 ES 的操作后,QPS 达到 110 k,是之前 QPS 的十倍。由此可以基本判定: ES 集群写性能导致的上游反压
优化方向
索引字段类型调整
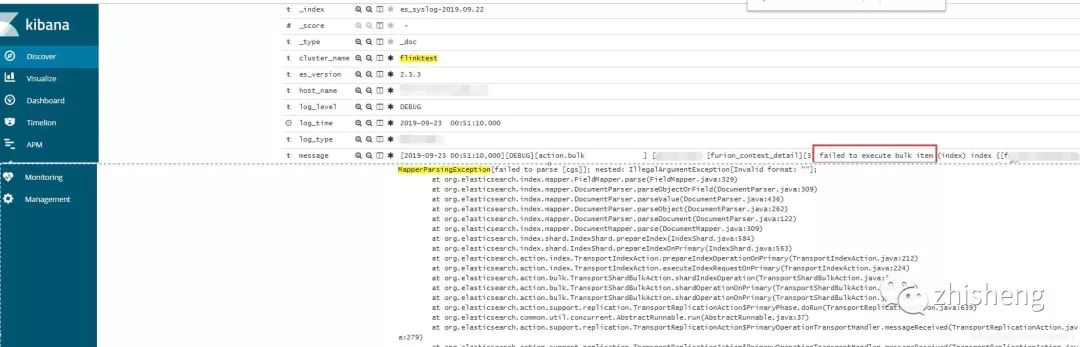
bulk 失败的原因是由于集群 dynamic mapping 自动监测,部分字段格式被识别为日期格式而遇到空字符串无法解析报错。
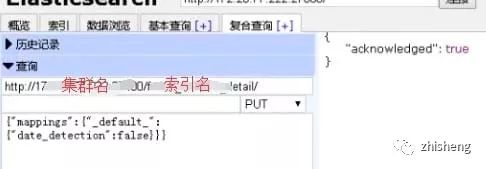
解决方案:关闭索引自动检测。
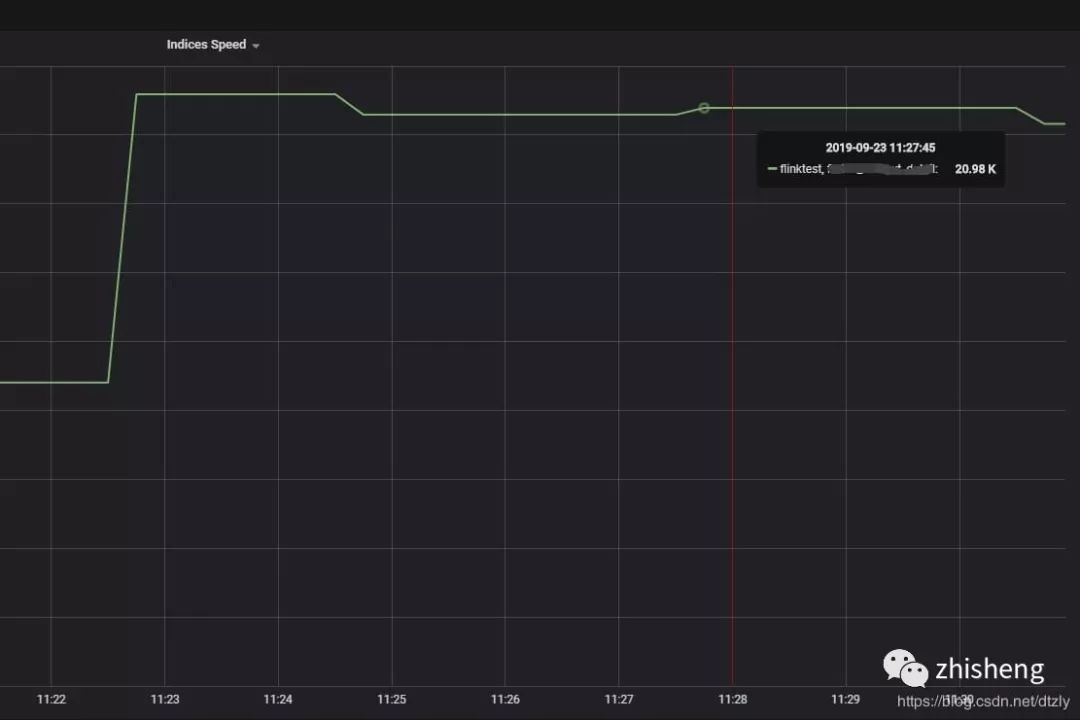
效果: ES 集群写入性能明显提高但 Flink operator 依然存在反压:
降低副本数
提高 refresh_interval
针对这种 ToB、日志型、实时性要求不高的场景,我们不需要查询的实时性,通过加大甚至关闭 refresh_interval 的参数提高写入性能。
检查集群各个节点 CPU 核数
在 Flink 执行时,通过 Grafana 观测各个节点 CPU 使用率以及通过 Linux 命令查看各个节点 CPU 核数。发现 CPU 使用率高的节点 CPU 核数比其余节点少。为了排除这个短板效应,我们将在这个节点中的索引 shard 移动到 CPU 核数多的节点。
curl -XPOST {集群地址}/_cluster/reroute -d'{"commands":[{"move":{"index":"{索引名称}","shard":5,"from_node":"源node名称","to_node":"目标node名称"}}]}' -H "Content-Type:application/json"以上优化的效果:
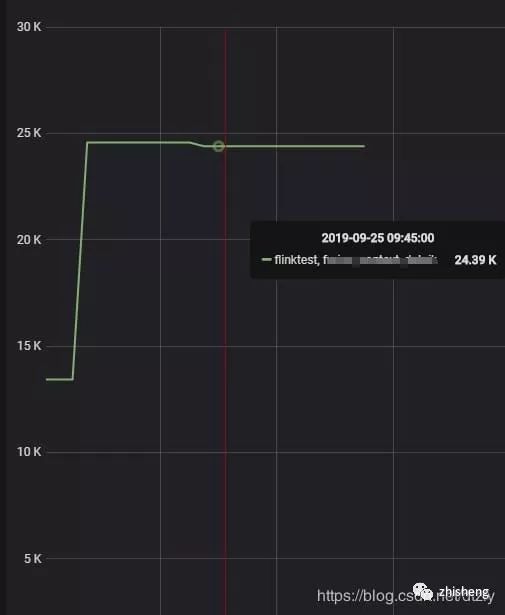
经过以上的优化,我们发现写入性能提升有限。因此,需要深入查看写入的瓶颈点。
在 CPU 使用率高的节点使用 Arthas 观察线程
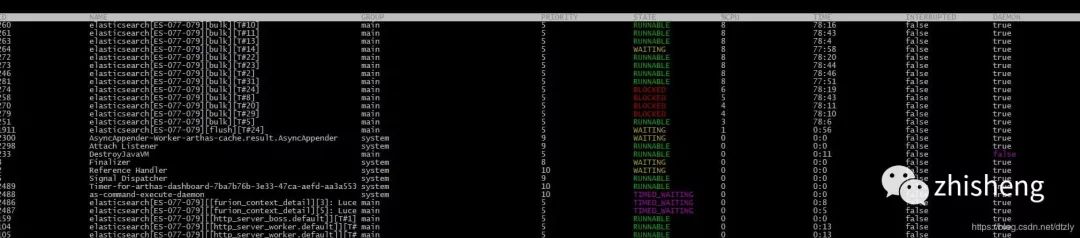
打印阻塞的线程堆栈
"elasticsearch[ES-077-079][bulk][T#3]" Id=247 WAITING on java.util.concurrent.LinkedTransferQueue@369223fa
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.LinkedTransferQueue@369223fa
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.LinkedTransferQueue.awaitMatch(LinkedTransferQueue.java:737)
at java.util.concurrent.LinkedTransferQueue.xfer(LinkedTransferQueue.java:647)
at java.util.concurrent.LinkedTransferQueue.take(LinkedTransferQueue.java:1269)
at org.elasticsearch.common.util.concurrent.SizeBlockingQueue.take(SizeBlockingQueue.java:161)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)从上面的线程堆栈我们可以看出线程处于等待状态。
关于这个问题的讨论详情查看 https://discuss.elastic.co/t/thread-selection-and-locking/26051/3,这个 issue 讨论大致意思是:节点数不够,需要增加节点。于是我们又增加节点并通过设置索引级别的 total_shards_per_node 参数将索引 shard 的写入平均到各个节点上。
线程队列优化
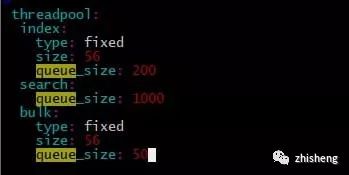
ES 是将不同种类的操作(index、search…)交由不同的线程池执行,主要的线程池有三:index、search 和 bulk thread_pool。线程池队列长度配置按照官网默认值,我觉得增加队列长度而集群本身没有很高的处理能力线程还是会 await(事实上实验结果也是如此在此不必赘述),因为实验节点机器是 56 核,对照官网:

因此修改 size 数值为 56。
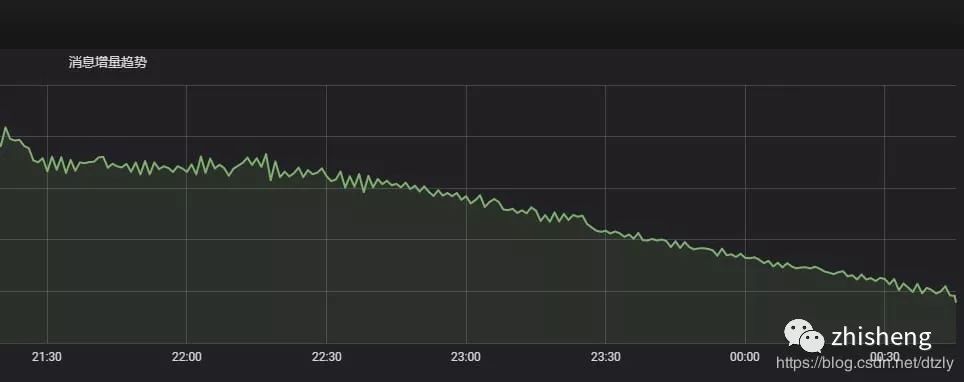
经过以上的优化,我们发现在 kafka 中的 topic 积压有明显变少的趋势:
index buffer size 的优化
参照官网:

translog 优化:
索引写入 ES 的基本流程是:
数据写入 buffer 缓冲和 translog;
每秒 buffer 的数据生成 segment 并进入内存,此时 segment 被打开并供 search 使用查询;
buffer 清空并重复上述步骤 ;
buffer 不断添加、清空 translog 不断累加,当达到某些条件触发 commit 操作,刷到磁盘;
ES 默认的刷盘操作为 Request 但容易部分操作比较耗时,在日志型集群、允许数据在刷盘过程中少量丢失可以改成异步 async。
另外一次 commit 操作是在 translog 达到某个阈值执行的,可以把大小(flush_threshold_size )调大,刷新间隔调大。
index.translog.durability : async
index.translog.flush_threshold_size : 1gb
index.translog.sync_interval : 30s效果:
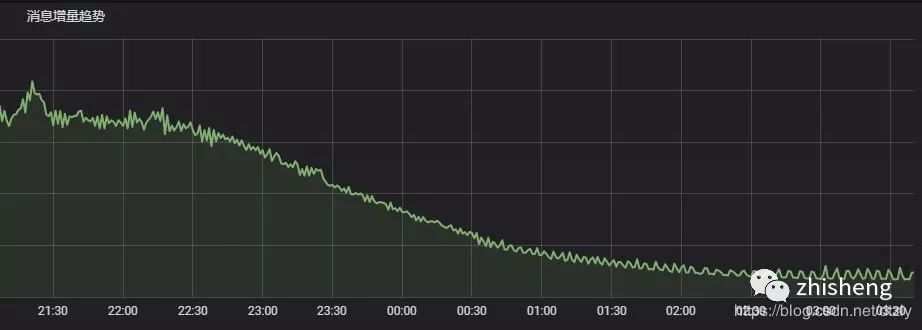
Flink 反压从打满 100% 降到 40%(output buffer usage):

kafka 消费组里的积压明显减少:
总结
当 ES 写入性能遇到瓶颈时,我总结的思路应该是这样:
看日志,是否有字段类型不匹配,是否有脏数据。
看 CPU 使用情况,集群是否异构
客户端是怎样的配置?使用的 bulk 还是单条插入
查看线程堆栈,查看耗时最久的方法调用
确定集群类型:ToB 还是 ToC,是否允许有少量数据丢失?
针对 ToB 等实时性不高的集群减少副本增加刷新时间
index buffer 优化 translog 优化,滚动重启集群
Apache Flink 及大数据领域盛会 Flink Forward Asia 2019 将于 11月28-30日在北京举办,阿里、腾讯、美团、字节跳动、百度、英特尔、DellEMC、Lyft、Netflix 及 Flink 创始团队等近 30 家知名企业资深技术专家齐聚国际会议中心,与全球开发者共同探讨大数据时代核心技术与开源生态。点击「阅读原文」了解更多精彩议程。
▼
智能推荐
Web安全之文件包含漏洞_allow_url_fopen http 文件包含-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏3次。什么是文件包含程序开发人员一般会把重复使用的函数写到单个文件中,需要使用某个函数时直接调用此文件。而无需再次编写,这种 文件调用的过程一般被称为文件包含。例如:include “conn.php”PHP中常见包含文件函数include()当使用该函数包含文件时,只有代码执行到include()函数时才将文件包含进来,发生错误时之给出一个警告,继续向下执行。include_once()..._allow_url_fopen http 文件包含
MySQL安装配置教程最全详解,一步一图解_mysql安装教程图解-程序员宅基地
文章浏览阅读820次,点赞14次,收藏6次。这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。(img-tcUzaO6d-1713163585912)]同时非常期待小伙伴们能够关注,后面慢慢推出更好的干货~嘻嘻。如果有写得不正确的地方,麻烦指出,感激不尽。
node-sass 安装失败解决办法_nodesass安装报错-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏6次。很多小伙伴在安装node-sass的时候都失败了,主要的原因是node版本和项目依赖的node-sass版本不匹配。node-sass依赖node版本,而sass则不需要。解决方案:卸载node-sass,安装sass,项目全局搜索/deep/, 把/deep/替换为::v-deep即可。_nodesass安装报错
map 和 flatMap 区别_flatmap和map区别-程序员宅基地
文章浏览阅读1.9w次,点赞30次,收藏47次。区别这两个在本质上是一样的,都是 map 操作,即对流形式的传入数据进行处理返回一个数据。但是区别方面从字面上就可以体现出来,flatMap 比 map 多了一个 flat 操作,也就是 “展平/扁平化” 处理的意思。所以 flatMap 是一个 map 和一个 flat 操作的组合。其首先将一个函数应用于元素,然后将其展平,当你需要将 [[a,b,c],[d,e,f],[x,y,z]] 具有两个级别的数据结构转换为 [a,b,c,d,e,f,x,y,z] 这样单层的数据结构时,就选择使用 flatMa_flatmap和map区别
Unigine入门知识散记(一)_unigine怎么在y轴移动-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏2次。1、Unigine里面的node相当于Unity里面的gameObject,在Unity中,gameObject至少有一个Transform组件,Unigine的开发者可能认为既然Transform是必有的组件,那把这个组件做成node的属性算了,所以在Unigine中node自带Transform的主要功能。2、Unigine中的Input类和Unity中的Input类非常类似,很多功能可以对照一下:Unity的Input方法 Unigine的Input方法 GetKeyDown _unigine怎么在y轴移动
oracle数据库查看版本号_navicat查看oracle版本-程序员宅基地
文章浏览阅读6.6k次。1、使用Navicat连接数据库。oracle数据库查看版本号。2、打开数据库并新建查询。_navicat查看oracle版本
随便推点
python ttk separator_python - ttk.Separator设置长度/宽度 - 堆栈内存溢出-程序员宅基地
文章浏览阅读645次。如何在Tkinter中设置/更改ttk.Separator对象的长度/宽度?ttk.Separator(self, orient='horizontal').grid(column=0,row=0, columnspan=2, sticky='ew')看起来柱子试图完成这项工作,但是当你有多个具有相同列宽的分隔符时,它们似乎有不同的长度 - 任何想法为什么?这是一个简单快速的特殊“脏”测试示例:i..._tkinter seperator 宽度
Could not find bundle: org.eclipse.equinox.console-程序员宅基地
文章浏览阅读1.6k次。问题 描述: org.osgi.framework.BundleException: Could not find bundle: org.eclipse.equinox.console 解决方案如下步骤一:eclipse.ini 设置 jdk 在vm 后加上/usr/java/jre1.7.0_06/bin/java设置前-startupplugins/org.eclipse.equin_could not find bundle: org.eclipse.equinox.console
使用RPA通过GPT大模型AI Agent自动执行业务流程任务企业级应用开发实战: 设计 AI Agent 的架构-程序员宅基地
文章浏览阅读198次,点赞2次,收藏2次。在本章中,将详细阐述GPT-3的架构和功能。包括了GPT-3模型结构、计算框架、并行计算特性等。GPT-3模型是一种基于预训练语言模型的方法,可以生成连续文本或长文本。同时它还拥有基于规则、推理、决策、分类等多种功能,能够根据输入完成特定任务。GPT-3的产生离不开深度学习的革命性突破。首先,是GPT-3模型结构:GPT-3模型是一个联合型的神经网络。输入是一些词语或短语,输出则是对应的连贯句子或者长段文本。整个模型由encoder和decoder组成,前者主要用于文本处理,后者则是用来生成结果的解码器。
【已解决】【V3版本】如何使用脚本关闭Win10自动更新服务并阻止其自动启动?_usosvc-程序员宅基地
文章浏览阅读6.5k次,点赞16次,收藏38次。亲测: 在Windows安装后不要删除XBox及相关应用可以避免更新失败并反复重启的问题.介绍:该脚本可以关闭"usosvc"(Win10自动更新服务),并阻止其自动启动;需要再次运行脚本,并选择恢复,才能启动"usosvc"(Win10自动更新服务);该脚本的原理是,在注册表的"usosvc"目录项下,增加一个"WOW64"值,数据为"dword:0000014c";该值会阻止usosvc服务的启动;需要恢复的时候删除此值即可;相对于彻底删除服务的方法,此方法改动小,风险小,但可能_usosvc
踏板车的节油措施汇总-程序员宅基地
文章浏览阅读314次。四冲踏板摩托节油措施汇总 [08年版本] 〔序〕四冲活塞式内燃机是一种结构比较麻烦的发动机,靠皮带变速传动的踏板车是一种结构复杂毛病较多的车种;08年在ZJ搞研发的日子里,对这些踏板车又有了些新的进展;在此增添些新内容,仅供版内车友参考。 一、踏板车节油的意义:虽然有些人不在乎多消耗点燃油费,但机动车辆节油的意义不只是私人经济开销问题,而是事关环保大局。有点机车常识的人都应该知道,多供给发..._关闭电热加浓
gitlab仓库完整迁移(代码,分支,提交记录)_gitlab new directory-程序员宅基地
文章浏览阅读2.7k次。背景代码仓库所在服务器因为异常断电关机,无法启动,需要进行gitlab工程代码迁移命令git clone --mirror <URL to my OLD repo location>cd <New directory where your OLD repo was cloned>git remote set-url origin <URL to my NEW repo location>git push -f origin..._gitlab new directory