linux查pandas版本,Linux 查看 pandas-程序员宅基地
技术标签: linux查pandas版本
引用来自“007”的评论
(tf) [root@bogon testpd]# cat test.csv
A,B,C,D,code
1,2,3,4,23
5,6,7,7,234
23,423,4,21,123
(tf) [root@bogon testpd]# python
Python 3.6.6 (default, Aug 13 2018, 18:24:23)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> names = ['A','x','C','D','code','xxx','yyy']
>>> opcsv=pd.read_csv('test.csv', header=0, dtype={'code':str})
>>> opcsv
A B C D code
0 1 2 3 4 23
1 5 6 7 7 234
2 23 423 4 21 123
>>> opcsv.columns = names[:len(opcsv.columns)]
>>> opcsv
A x C D code
0 1 2 3 4 23
1 5 6 7 7 234
2 23 423 4 21 123
>>>
opcsv=pandas.read_csv(f,header=0,dtype={'code':str})
opcsv.reindex(columns=names)
请问我不太懂reindex(columns=names)是实现什么的 我尝试了一下似乎没有生效
看下结果是不是你要的效果
(tf) [root@bogon testpd]# cat test.csv
A,B,C,D,code
1,2,3,4,23
5,6,7,7,234
23,423,4,21,123
(tf) [root@bogon testpd]# python
Python 3.6.6 (default, Aug 13 2018, 18:24:23)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> names = ['A','B','C','D','code','xxx','yyy']
>>> opcsv=pd.read_csv('test.csv', header=0, dtype={'code':str})
>>> opcsv
A B C D code
0 1 2 3 4 23
1 5 6 7 7 234
2 23 423 4 21 123
>>> newpocsv = opcsv.reindex(columns=names)
>>> newpocsv
A B C D code xxx yyy
0 1 2 3 4 23 NaN NaN
1 5 6 7 7 234 NaN NaN
2 23 423 4 21 123 NaN NaN
>>>
是的!这正是我想要的结果,但是不知道为什么我按照您给的代码尝试了一遍发现,列名并没有成功生效。
以下是我打印调试的结果,由上面的list替换下面dataframe的表头
但令我无奈的是他并没有生效,我也不清楚具体的原因
是的!这正是我想要的结果,但是不知道为什么我按照您给的代码尝试了一遍发现,列名并没有成功生效。
以下是我打印调试的结果,由上面的list替换下面dataframe的表头
但令我无奈的是他并没有生效,我也不清楚具体的原因
回复 @007 : 我通过回复成功实现了,但又引发了新的问题
opcsv = opcsv.reindex(columns=names)
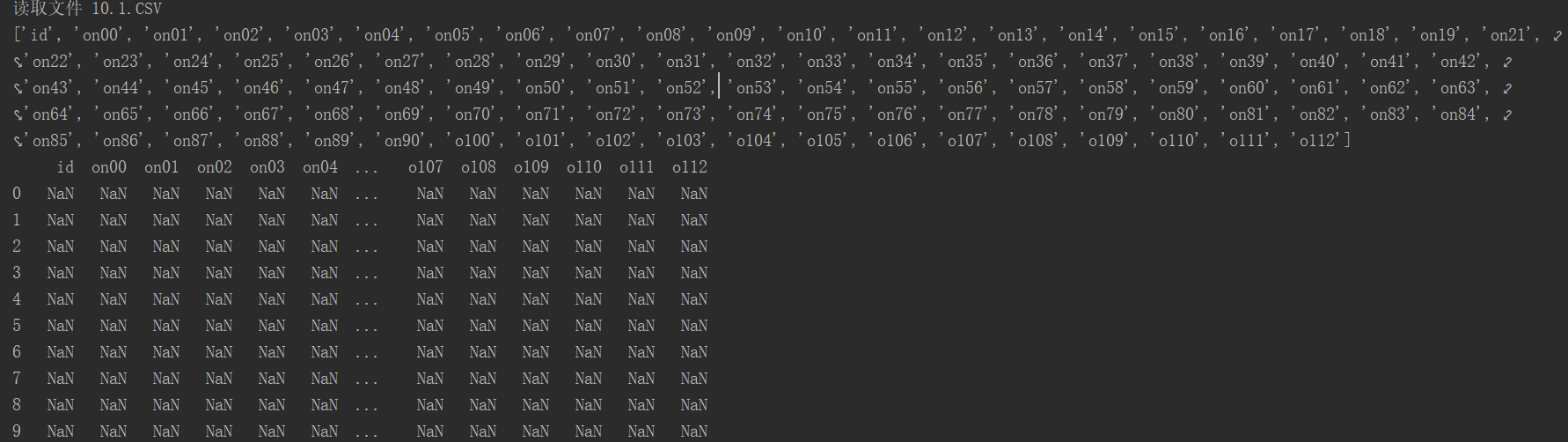
原有的数据也被全部清空赋值NaN了。我不清楚具体原因,我现在正尝试断点debug查看问题所在
当我在debug的时候发现了这样的报错
Traceback (most recent call last): File "E:\Program Files (x86)\PyCharm 2018.1.3\helpers\pydev\pydevd.py", line 1664, in main() File "E:\Program Files (x86)\PyCharm 2018.1.3\helpers\pydev\pydevd.py", line 1658, in main globals = debugger.run(setup['file'], None, None, is_module) File "E:\Program Files (x86)\PyCharm 2018.1.3\helpers\pydev\pydevd.py", line 1068, in run pydev_imports.execfile(file, globals, locals) # execute the script File "E:\Program Files (x86)\PyCharm 2018.1.3\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile exec(compile(contents+"\n", file, 'exec'), glob, loc) File "C:/Users/Administrator/Desktop/computerXP/hebing.py", line 2, in import pymysql,pandas,os,time,numpy File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\__init__.py", line 19, in "Missing required dependencies {0}".format(missing_dependencies)) ImportError: Missing required dependencies ['numpy']
我不知道是否是他的原因
我似乎找到了原因
frame = pd.DataFrame(np.arange(9).reshape((3, 3)), index=['a', 'c', 'd'], columns=['c1', 'c2', 'c3']) print frame
因为我本地读取的csv文件是
这样的中文列名,而我需要替换以下列名
因此就好在替换成功的同时将所有原来的数据变为NaN
因为如果从read_csv传参names来更改列名就必须要小于等于csv列数
或者如果只要解决names参数传入的元素少于csv列数dataframe从后抛弃数据这样是否可行?
(tf) [root@bogon testpd]# cat test.csv
A,B,C,D,code 1,2,3,4,23 5,6,7,7,234 23,423,4,21,123 (tf) [root@bogon testpd]# python Python 3.6.6 (default, Aug 13 2018, 18:24:23) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import pandas as pd >>> names = ['A','x','C','D','code','xxx','yyy'] >>> opcsv=pd.read_csv('test.csv', header=0, dtype={'code':str}) >>> opcsv A B C D code 0 1 2 3 4 23 1 5 6 7 7 234 2 23 423 4 21 123 >>> opcsv.columns = names[:len(opcsv.columns)] >>> opcsv A x C D code 0 1 2 3 4 23 1 5 6 7 7 234 2 23 423 4 21 123 >>>
我的天,简直不敢相信,这正是我想要得完美结果,请问您是做了理解pandas多深才做到的。能分享一下您是怎么去剖析pandas得到的
智能推荐
为什么我们需要企业架构?_企业架构的价值-程序员宅基地
文章浏览阅读1.8k次。良好的IT信息化建设基于两个前提:IT架构与业务价值,缺一不可,二者结合在一起就叫企业架构。IT架构服务于业务价值,而业务价值则通过业务架构来表现出来。_企业架构的价值
C++ Primer Plus(第六版)第9章 内存空间和名称空间_autoscp.cpp-程序员宅基地
文章浏览阅读549次。按住ctrl键选中三个执行文件,用debug模式进行调试。coordin.h// coordin.h -- structure templates and function prototypes// structure templates#ifndef COORDIN_H_#define COORDIN_H_struct polar{ double distance; // distance from origin double angle; // ._autoscp.cpp
倾斜摄影数据OSGB转换成3DML(转载)-程序员宅基地
文章浏览阅读2k次。工具/原料skyline CityBuilder方法/步骤确定手中的osgb数据文件夹符合命名规则,如下图打开CityBuilder(软件许可目前只能申请试用),在工具栏Mesh Layer的下拉选项中选择Import OSGB Layer,弹出相应对话框,在对话框Input folder后的Browse选择上图中的上级文件夹,选择后对话框中的后两项会自动填充,将Metedat..._osgb转skyline
一文搞懂文件系统-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏13次。文件系统是计算机操作系统中的一个核心组件,用于管理计算机中的文件和文件夹。它提供了一种组织和访问计算机存储设备上数据的方式。文件系统使用户能够创建、修改、删除和查找文件,以及组织文件和文件夹的层次结构。_文件系统
R绘制基于Cox回归模型的限制性立方样条图_限制性立方样条 cox 模型-程序员宅基地
文章浏览阅读1.4k次,点赞26次,收藏34次。R绘制基于Cox回归模型的限制性立方样条图。_限制性立方样条 cox 模型
java常见面试题(160道)_java面试题-程序员宅基地
文章浏览阅读5.4w次,点赞89次,收藏746次。java常见面试题_java面试题
随便推点
前端开发之Dom的简介和Dom操作_前端dom是什么意思啊-程序员宅基地
文章浏览阅读1.7k次。Dom的简介,Dom获取元素节点,Dom的获取父字关系节点,DOM节点创建,插入,删除,复制节点,设置节点的属性_前端dom是什么意思啊
android开发书籍下载,Android性能优化面试题集锦-程序员宅基地
文章浏览阅读511次,点赞14次,收藏9次。最后看一下学习需要的所有知识点的思维导图。在刚刚那份学习笔记里包含了下面知识点所有内容!文章里已经展示了部分!如果你正愁这块不知道如何学习或者想提升学习这块知识的学习效率,那么这份学习笔记绝对是你的秘密武器!
配置ACL包过滤防火墙典型实验_acl防火墙配置实验-程序员宅基地
文章浏览阅读2.8k次。配置ACL包过滤防火墙_acl防火墙配置实验
吴恩达《机器学习》12-4-12-5:核函数 1、核函数 2_核函数吴恩达-程序员宅基地
文章浏览阅读968次,点赞25次,收藏17次。当实例与地标距离近时,新特征的值趋近于 1,而当距离较远时,新特征的值趋近于 0。在实际应用中,通过选取不同的地标和核函数,能够构建出更加复杂且适应性强的判定边界,从而提高模型的性能。核函数的选择影响了特征的映射效果,而合适的核函数能够在新的特征空间中更好地划分不同类别。因此,需要一种更有效的方法来构造新的特征。核函数的作用在于将实例的原有特征映射到一个新的空间,从而使得在这个新空间中的判定边界更为有效。相应地,代价函数也需要进行调整,其中对于正则化项的计算引入了一个矩阵 M,该矩阵取决于选择的核函数。_核函数吴恩达
org.apache.commons.io.FileUtils 文件操作-程序员宅基地
文章浏览阅读1.1k次。转自:org.apache.commons.io——FileUtils学习笔记 FileUtils类的应用1、写入一个文件;2、从文件中读取;3、创建一个文件夹,包括文件夹;4、复制文件和文件夹;5、删除文件和文件夹;6、从URL地址中获取文件;7、通过文件过滤器和扩展名列出文件和文件夹;8、比较文件内容;9、文件最后的修改时间;10、计算校验和。..._apache common 文件夹创建
EV/HEV中的牵引逆变器驱动优化-程序员宅基地
文章浏览阅读1.6k次,点赞42次,收藏35次。什么是牵引逆变器?从本质上讲,牵引逆变器是电动汽车动力系统中的一个子系统,它从电池中获取高电压,并将其转换为交流电压——因此被称为逆变器——并基本上为电机供电。它控制电机速度和扭矩,直接影响效率和可靠性,这正成为牵引逆变器设计的设计挑战。此图片来源于网络如今的电动汽车至少有一个牵引逆变器。有些型号实际上不止一个。一个在前轴上,一个在后轴上。甚至一些高端车型实际上每个车轮都有一个牵引逆变器。因此,效率和可靠性非常重要。所以,从逆变器和电机控制的市场趋势来看——从技术趋势来看,我们看到了功率水平的提高。