电商客户价值细分 - RFM 模型(中)_rfm使用均值还是中位数判断价值-程序员宅基地
技术标签: python 数据分析 big data 数据挖掘 Python 开发语言
4.1 RFM 模型的概念
RFM 模型是一个传统的数据分析模型,沿用至今约 60 年。
1961 年,乔治·卡利南在顾客的资料库中指出,最近一次消费、消费频率、消费金额三项数据可以较为客观地描绘顾客的轮廓。
企业针对近期有消费的“新客”、消费频率高的“常客”、消费金额高的“贵客”进行精准营销和广告投放,确实收到了意料之外的惊喜。
因此,这三项数据成为了衡量客户价值和客户创利能力的重要工具和手段。也是 RFM 模型的三个重要指标:
1)R(Recency):最近一次消费时间间隔,指用户最近一次消费时间距离现在的时间间隔;
2)F(Frequency):消费频率,指用户一段时间内消费了多少次;
3)M(Monetary):消费金额,指用户一段时间内的消费金额。

这里举个例子来说明 3 个指标是什么意思。
小钟有一家店铺,小王是这家店的用户,今天是 12 月 31 号。
小王最近一次在店铺买东西是这个月 12 号,最近一次消费距离现在过去了 19 天,所以小王的最近一次消费时间间隔(R)是 19 天。
如果我们对“一段时间”的定义是 12 月,该月小王在店铺有 2 次消费记录,那么小王的消费频率(F)是 2 次。
小王在 2 次消费过程中共消费 1314 元,则小王的消费金额(M)为 1314 元。
3 个指标针对的业务不同,定义也会有所不同。但是无论是什么业务,各指标都有如下的特征:
1)最近一次消费时间间隔(R):上一次消费时间离现在越近,再次消费的几率越大。即 R 值越小,用户的活跃度越大,用户的价值就越高;
2)消费频率(F):购买频率越高,说明用户对品牌产生一定的信任和情感维系。即 F 值越大,用户的忠诚度就越大,用户的价值就越高;
3)消费金额(M):消费金额越高,说明用户对产品的购买力越大。即 M 值越大,用户的购买力就越大,用户的价值就越高。
有高价值用户的存在,自然也会有低价值用户的存在,即每个指标数据的价值都有高低两种情况。
因此,把 3 个指标的价值组合起来看,会有 2 x 2 x 2 = 8 种组合。
如果把 R、F、M 的价值高低作为坐标轴,可以将用户划分为下图的 8 个类型:
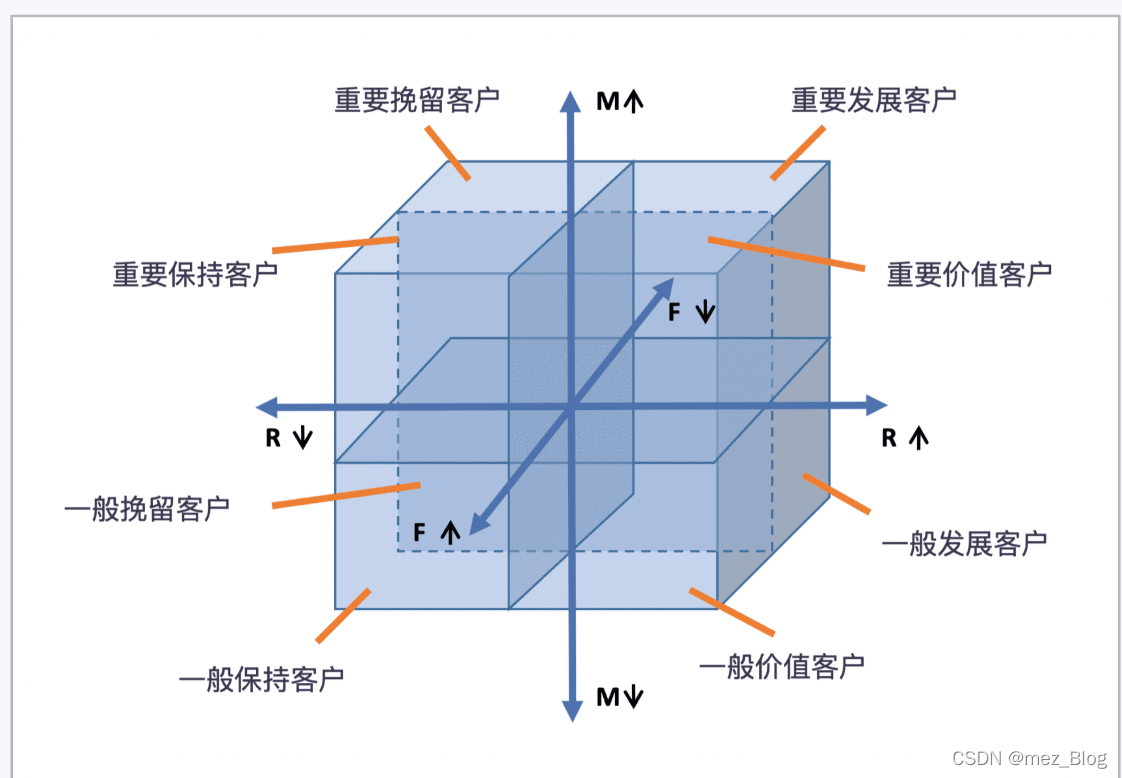
再将上图中的用户分类进行总结,可以得到下图的用户分类规则表。
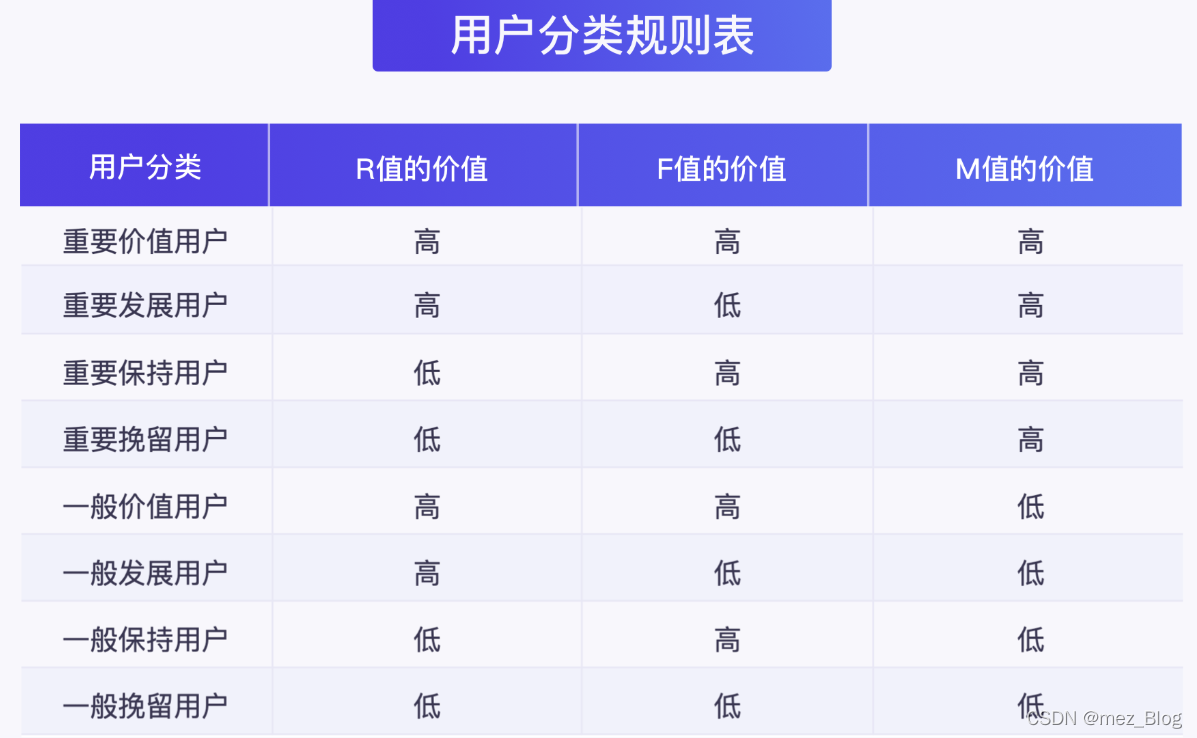
据 RFM 模型得到用户的分类后有什么用呢?一起来看下它的作用。
4.2 RFM 模型的作用
RFM 模型多用于精细化运营服务。单看 R、F、M 三个指标,其本身已经具备了一定的参考性:
一般来说,比起许久没有消费的顾客,消费时间间隔短的客户再次购买的几率较高。针对这类客户,可以采取唤醒或者刺激消费,如赠送打折券等。
消费频率高的客户,其忠诚度相对较高,可以规律性地提醒这类客户关于产品的一些优惠信息。
消费金额高的客户,客户价值也越高,可以提供专属该类客户的优惠价格。

如果根据 RFM 模型将用户细分为 8 类,还能进一步对不同价值的用户使用不同的运营策略,获取并保留关键性用户,针对价值高的客户制定促销策略。
比如重要价值用户,这类用户最近一次消费时间较近,消费频率高,消费金额高,需要提供 VIP 服务和个性化服务,提升品牌形象。
对于一般挽留用户,其最近一次消费时间较远,消费频率低,消费金额低,可以减少该类用户的营销成本和服务预算。
ok,RFM 模型的作用也了解完毕。接下来,我们具体看看 RFM 模型是如何根据用户分类规则表将用户分为 8 类。
4.3 RFM 模型的构建流程
4.3.1 计算 R、F、M 的值
得到 R、F、M 这 3 个指标,一般需要的信息有:用户名称/用户 ID、消费记录(如消费时间、消费金额)。
假设现在是 2020 年 12 月 30 日,分析最近 30 天有进行消费的用户。其中:
用户小许最近一次消费时间是 2020 年 12 月 12 日,与今天的时间间隔为 18 天。在该月总共消费了 2 次,总共消费金额是 2021 元。
用户小王最近一次消费时间是 2020 年 12 月 28 日,与今天的时间间隔为 2 天。在该月总共消费了 5 次,总共消费金额是 10000 元。
我们可以得到两个用户的 R、F、M 值,如下表所示:

.3.2 根据 RFM 的阈值,对用户进行分类
首先,我们了解一下什么叫阈值。
阈值,又叫临界值,是指一个效应能够产生的最低值或最高值。
比如日常生活中,煮开水会有一个“沸点”。当温度低于“沸点”时水还没煮开,当温度高于这个“沸点”时,水就煮沸腾了。
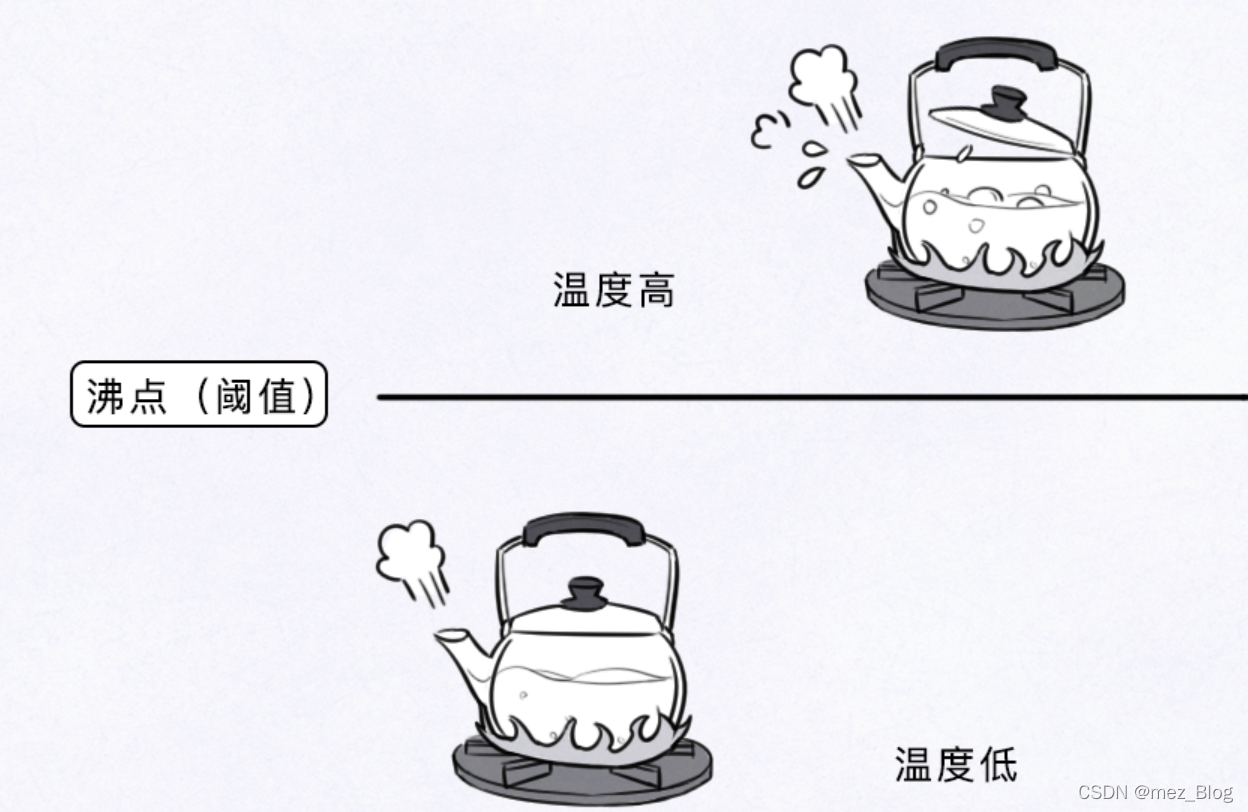
这里用来区分温度高低的“沸点”,就可以理解为阈值。
而在案例中,对 RFM 各值的高低值进行标记前,需要我们获得 RFM 各值的阈值。
获得阈值,可以对 RFM 各值采取分区域评分,再计算各值平均数的方式,该方式会分为三个步骤:
1)给 R、F、M 各值按价值划分打分区间
这里需要注意的是,我们不是按指标的数值大小打分,而是对指标的价值打分。像最近一次消费时间间隔(R),消费时间间隔最近,即 R 值越小,用户的价值越高。
如何定义打分的范围,需要结合具体的业务来调整。由于这里是举例子来说明,所以我假设 R、F、M 各值按价值从小到大分为 1~5 分,其打分规则如下表:
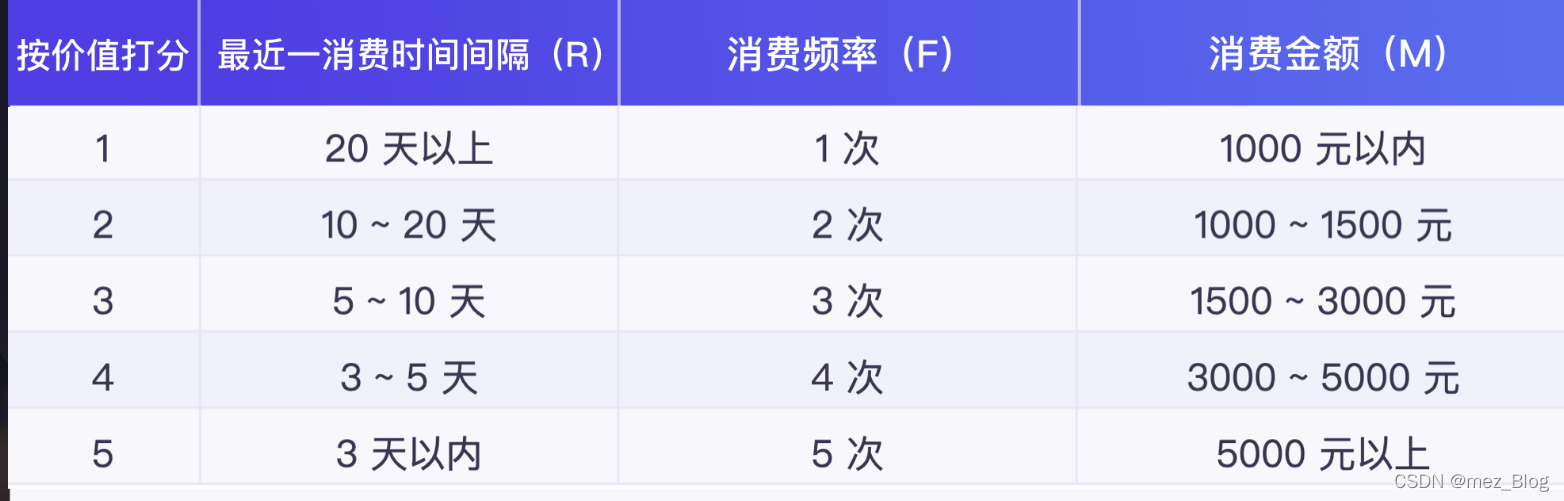
根据打分规则表,给两个用户的 RFM 值进行打分。

2)计算价值的平均值
打完分数后,分别计算 R、F、M 各打分值的平均值,结果如下:
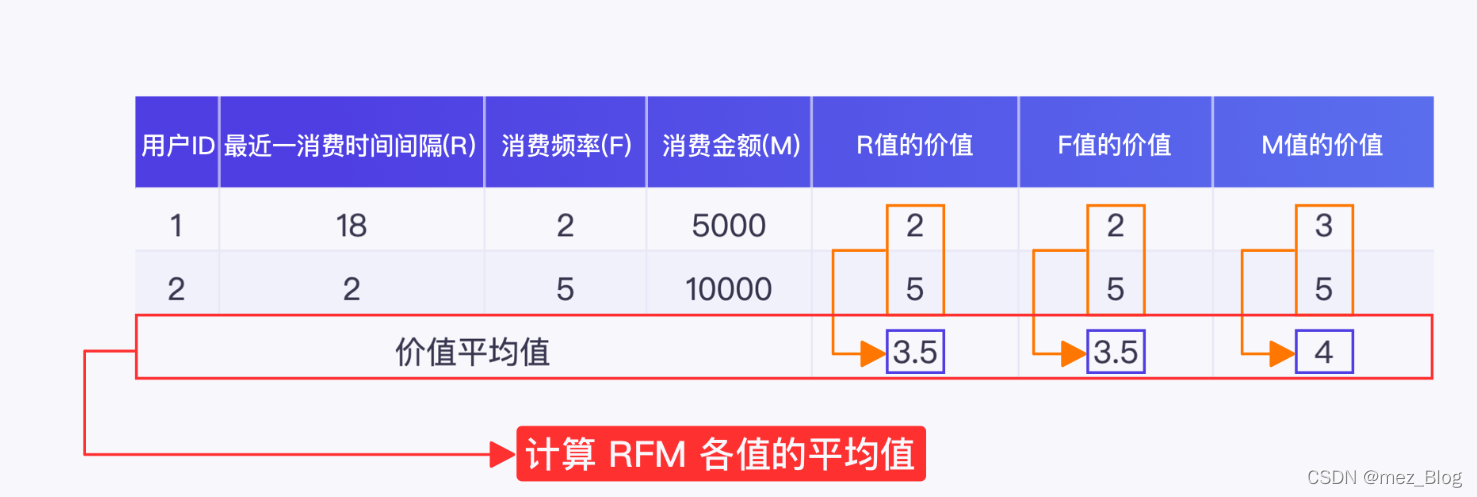
3)用户分类
最后,我们将两个用户的 RFM 值与各值的平均值进行对比。
如果一行里的 R 值打分大于平均值,就标记该行的 R 值标记为“高”,反之标记为“低”。F、M 值亦是同理。
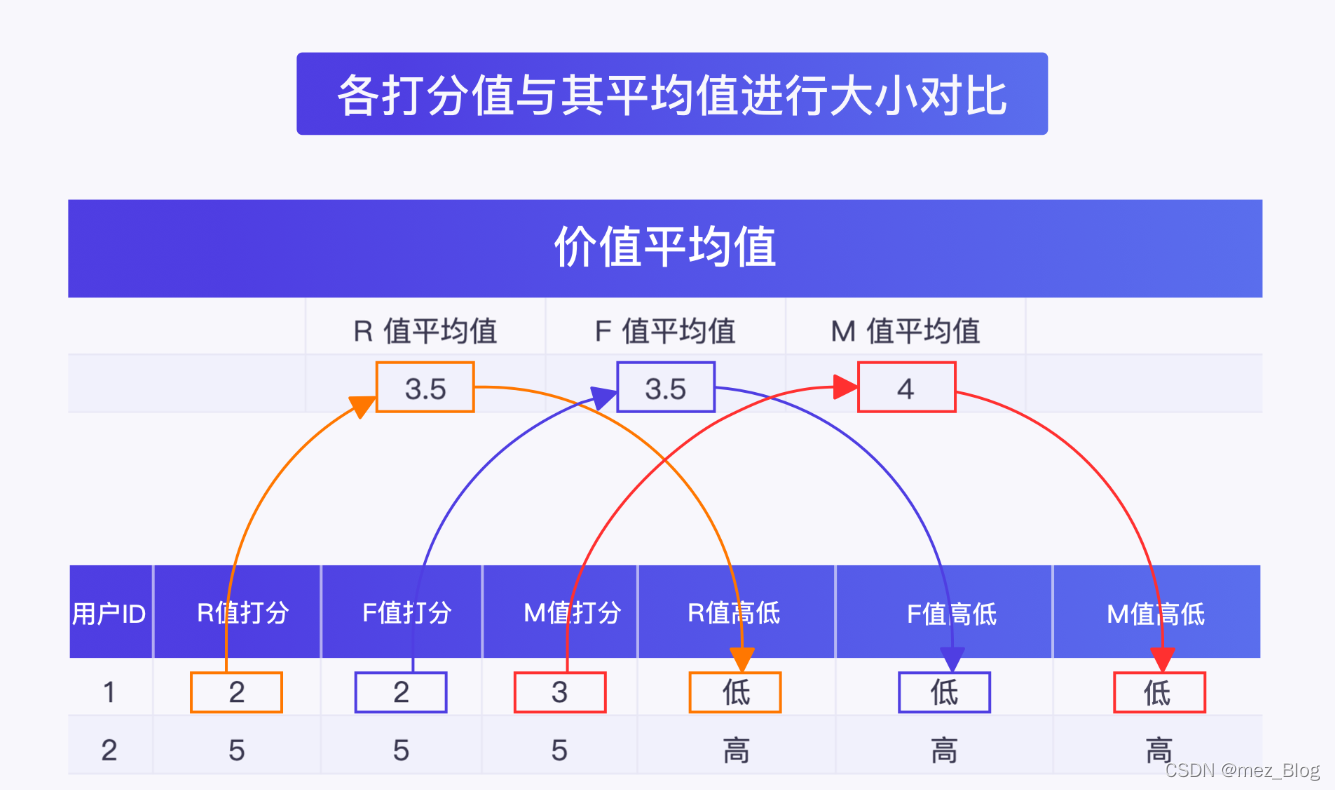
再将标记好的 RFM 高低值与用户分类规则表进行对比,可以得出用户属于哪种类别。
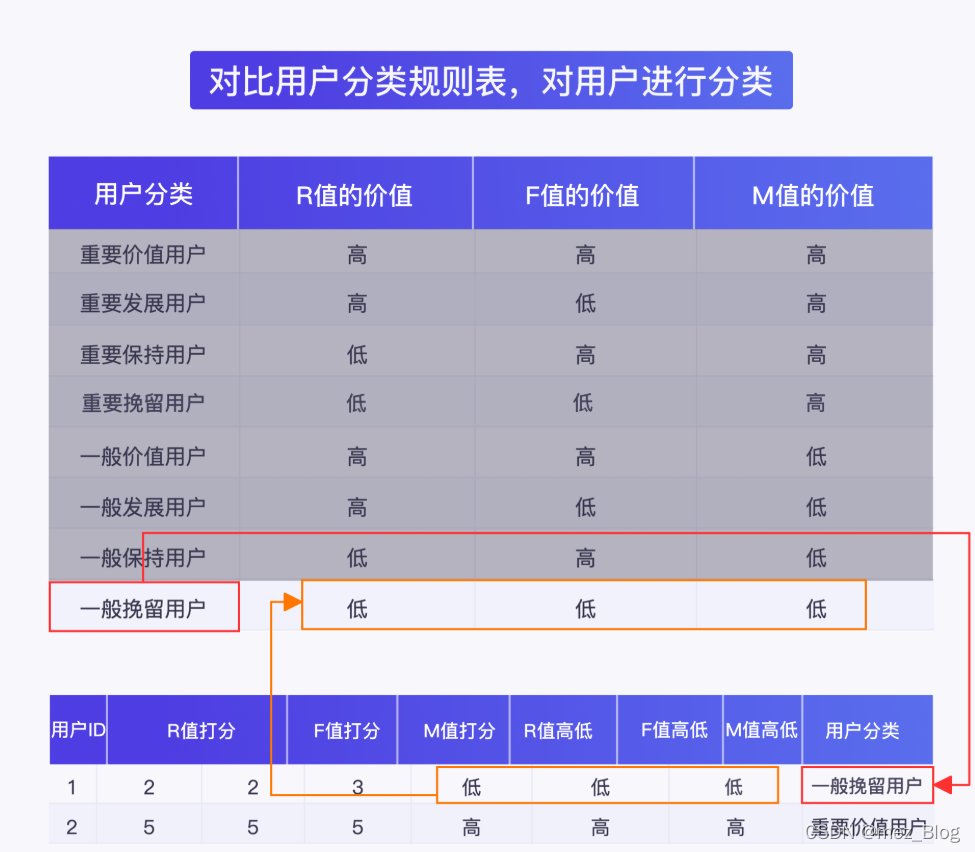
至此,我们学习完 RFM 模型将用户进行分类的操作。你可以查看下图,回顾 RFM 模型的构建流程。
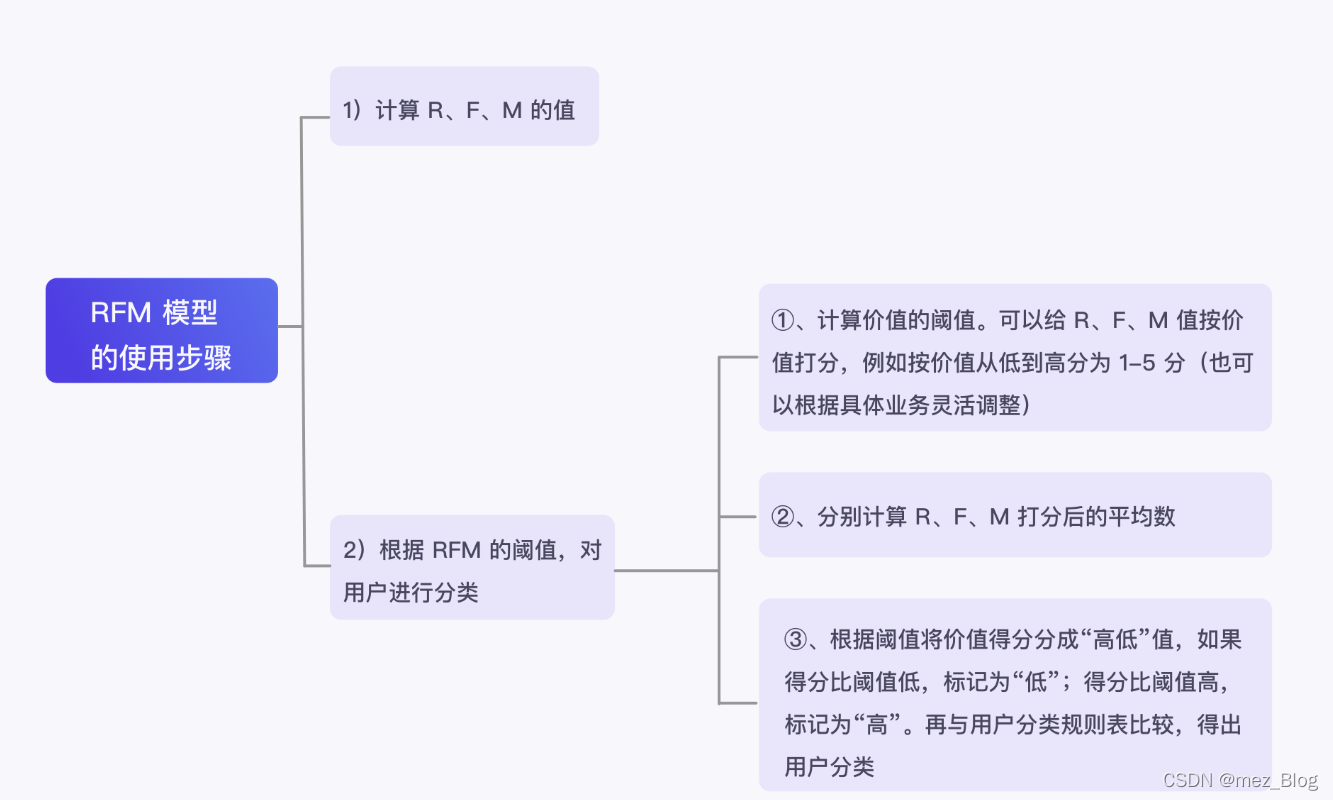
在构建 RFM 模型的过程中,有几个注意事项:
1)现实业务,不一定有完整的 RFM 数据,需要通过计算或变换。比如上方的 R 值,我们需要确定一个时间点,并计算该时间点与用户最近一次消费时间才能得到最小时间间隔。
2)划分 RFM 的“高低”值,关键是找到划分的阈值。分析目标的不同,所选择的分析方法也可能不同。
上面的例子中,我们为 RFM 各值进行分区域评分,再计算各评分值的平均值来得到阈值。
而在数据量大的情况下,其实我们也可以通过 R、F、M 各值的原始数据,直接计算平均数或中位数的方式来获得阈值,计算起来也相对简单。
只是选择计算平均数来获得阈值的方式,它有个缺点就是:容易受到极值的影响,无法根据业务需求人为控制。
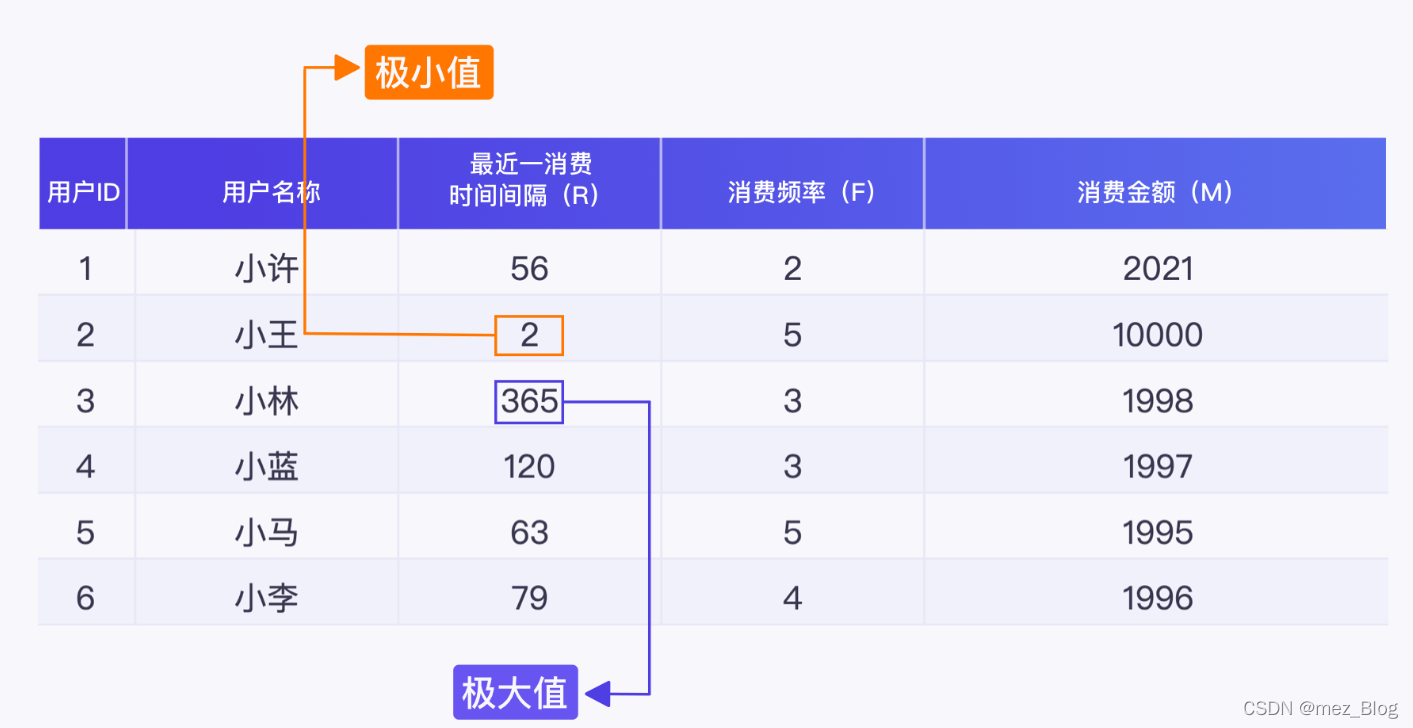
这样得到的阈值对 RFM 值进行高低档的标记,会给后面分析得到的用户分类带来误差。
为了不受到极值的影响,可以选择计算中位数来获得阈值。
但中位数也有一个缺点就是:容易受到数据分布的密集程度所影响,无法对分布密集的数据进行深入分析。
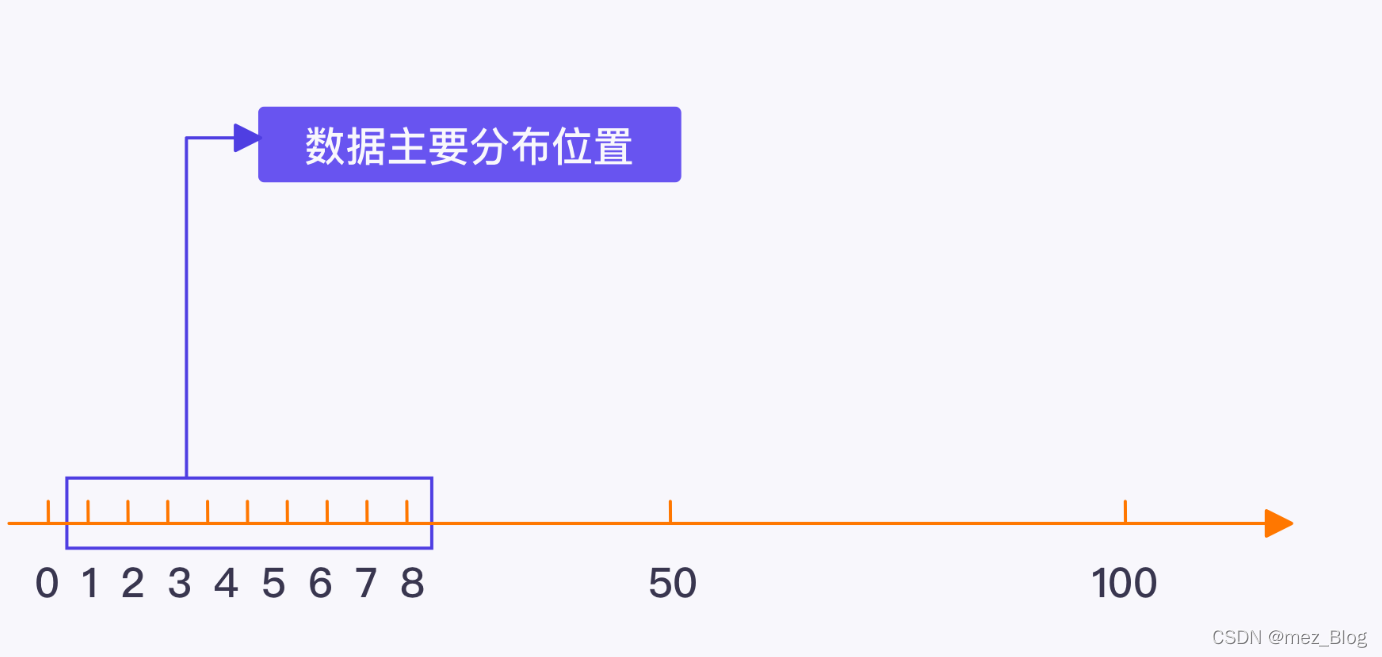
由此得出来的结果,可能也会影响到用户的分类。
因此,如果只是简单计算阈值,可以采取平均数或者中位数等方法。
而如果想不受数据分布密度的影响,并根据业务需求和资源进行调整,可以选择分区域评分,再计算平均值的分析方法;
5. 总结
基础知识
1)read_excel(io, sheet_name=0):读取 Excel 文件类型的数据;
2)to_excel(excel_writer, sheet_name='Sheet1', index=True):将数据写入到 Excel 类型的文件;
3)astype(dtype):转换数据的类型;
4)replace(to_replace):批量替换数据。
RFM 模型
1)RFM 模型的概念
a. R:最近一次消费时间间隔;
b. F:消费频率;
c. M:消费金额。
2)RFM 模型的作用:多用于精细化运营,了解用户分布情况。
3)RFM 模型的构建流程
a. 获取含有 RFM 的用户数据;
b. 根据 RFM 的阈值,对用户进行分类。

智能推荐
hive使用适用场景_大数据入门:Hive应用场景-程序员宅基地
文章浏览阅读5.8k次。在大数据的发展当中,大数据技术生态的组件,也在不断地拓展开来,而其中的Hive组件,作为Hadoop的数据仓库工具,可以实现对Hadoop集群当中的大规模数据进行相应的数据处理。今天我们的大数据入门分享,就主要来讲讲,Hive应用场景。关于Hive,首先需要明确的一点就是,Hive并非数据库,Hive所提供的数据存储、查询和分析功能,本质上来说,并非传统数据库所提供的存储、查询、分析功能。Hive..._hive应用场景
zblog采集-织梦全自动采集插件-织梦免费采集插件_zblog 网页采集插件-程序员宅基地
文章浏览阅读496次。Zblog是由Zblog开发团队开发的一款小巧而强大的基于Asp和PHP平台的开源程序,但是插件市场上的Zblog采集插件,没有一款能打的,要么就是没有SEO文章内容处理,要么就是功能单一。很少有适合SEO站长的Zblog采集。人们都知道Zblog采集接口都是对Zblog采集不熟悉的人做的,很多人采取模拟登陆的方法进行发布文章,也有很多人直接操作数据库发布文章,然而这些都或多或少的产生各种问题,发布速度慢、文章内容未经严格过滤,导致安全性问题、不能发Tag、不能自动创建分类等。但是使用Zblog采._zblog 网页采集插件
Flink学习四:提交Flink运行job_flink定时运行job-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏2次。restUI页面提交1.1 添加上传jar包1.2 提交任务job1.3 查看提交的任务2. 命令行提交./flink-1.9.3/bin/flink run -c com.qu.wc.StreamWordCount -p 2 FlinkTutorial-1.0-SNAPSHOT.jar3. 命令行查看正在运行的job./flink-1.9.3/bin/flink list4. 命令行查看所有job./flink-1.9.3/bin/flink list --all._flink定时运行job
STM32-LED闪烁项目总结_嵌入式stm32闪烁led实验总结-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏6次。这个项目是基于STM32的LED闪烁项目,主要目的是让学习者熟悉STM32的基本操作和编程方法。在这个项目中,我们将使用STM32作为控制器,通过对GPIO口的控制实现LED灯的闪烁。这个STM32 LED闪烁的项目是一个非常简单的入门项目,但它可以帮助学习者熟悉STM32的编程方法和GPIO口的使用。在这个项目中,我们通过对GPIO口的控制实现了LED灯的闪烁。LED闪烁是STM32入门课程的基础操作之一,它旨在教学生如何使用STM32开发板控制LED灯的闪烁。_嵌入式stm32闪烁led实验总结
Debezium安装部署和将服务托管到systemctl-程序员宅基地
文章浏览阅读63次。本文介绍了安装和部署Debezium的详细步骤,并演示了如何将Debezium服务托管到systemctl以进行方便的管理。本文将详细介绍如何安装和部署Debezium,并将其服务托管到systemctl。解压缩后,将得到一个名为"debezium"的目录,其中包含Debezium的二进制文件和其他必要的资源。注意替换"ExecStart"中的"/path/to/debezium"为实际的Debezium目录路径。接下来,需要下载Debezium的压缩包,并将其解压到所需的目录。
Android 控制屏幕唤醒常亮或熄灭_android实现拿起手机亮屏-程序员宅基地
文章浏览阅读4.4k次。需求:在诗词曲文项目中,诗词整篇朗读的时候,文章没有读完会因为屏幕熄灭停止朗读。要求:在文章没有朗读完毕之前屏幕常亮,读完以后屏幕常亮关闭;1.权限配置:设置电源管理的权限。
随便推点
目标检测简介-程序员宅基地
文章浏览阅读2.3k次。目标检测简介、评估标准、经典算法_目标检测
记SQL server安装后无法连接127.0.0.1解决方法_sqlserver 127 0 01 无法连接-程序员宅基地
文章浏览阅读6.3k次,点赞4次,收藏9次。实训时需要安装SQL server2008 R所以我上网上找了一个.exe 的安装包链接:https://pan.baidu.com/s/1_FkhB8XJy3Js_rFADhdtmA提取码:ztki注:解压后1.04G安装时Microsoft需下载.NET,更新安装后会自动安装如下:点击第一个傻瓜式安装,唯一注意的是在修改路径的时候如下不可修改:到安装实例的时候就可以修改啦数据..._sqlserver 127 0 01 无法连接
js 获取对象的所有key值,用来遍历_js 遍历对象的key-程序员宅基地
文章浏览阅读7.4k次。1. Object.keys(item); 获取到了key之后就可以遍历的时候直接使用这个进行遍历所有的key跟valuevar infoItem={ name:'xiaowu', age:'18',}//的出来的keys就是[name,age]var keys=Object.keys(infoItem);2. 通常用于以下实力中 <div *ngFor="let item of keys"> <div>{{item}}.._js 遍历对象的key
粒子群算法(PSO)求解路径规划_粒子群算法路径规划-程序员宅基地
文章浏览阅读2.2w次,点赞51次,收藏310次。粒子群算法求解路径规划路径规划问题描述 给定环境信息,如果该环境内有障碍物,寻求起始点到目标点的最短路径, 并且路径不能与障碍物相交,如图 1.1.1 所示。1.2 粒子群算法求解1.2.1 求解思路 粒子群优化算法(PSO),粒子群中的每一个粒子都代表一个问题的可能解, 通过粒子个体的简单行为,群体内的信息交互实现问题求解的智能性。 在路径规划中,我们将每一条路径规划为一个粒子,每个粒子群群有 n 个粒 子,即有 n 条路径,同时,每个粒子又有 m 个染色体,即中间过渡点的_粒子群算法路径规划
量化评价:稳健的业绩评价指标_rar 海龟-程序员宅基地
文章浏览阅读353次。所谓稳健的评估指标,是指在评估的过程中数据的轻微变化并不会显著的影响一个统计指标。而不稳健的评估指标则相反,在对交易系统进行回测时,参数值的轻微变化会带来不稳健指标的大幅变化。对于不稳健的评估指标,任何对数据有影响的因素都会对测试结果产生过大的影响,这很容易导致数据过拟合。_rar 海龟
IAP在ARM Cortex-M3微控制器实现原理_value line devices connectivity line devices-程序员宅基地
文章浏览阅读607次,点赞2次,收藏7次。–基于STM32F103ZET6的UART通讯实现一、什么是IAP,为什么要IAPIAP即为In Application Programming(在应用中编程),一般情况下,以STM32F10x系列芯片为主控制器的设备在出厂时就已经使用J-Link仿真器将应用代码烧录了,如果在设备使用过程中需要进行应用代码的更换、升级等操作的话,则可能需要将设备返回原厂并拆解出来再使用J-Link重新烧录代码,这就增加了很多不必要的麻烦。站在用户的角度来说,就是能让用户自己来更换设备里边的代码程序而厂家这边只需要提供给_value line devices connectivity line devices