【重识云原生】第六章容器6.1.5节——Docker核心技术Namespace_docker;nvme;namespace-程序员宅基地
技术标签: 云原生 linux chroot IPC Namespace 云原生-IaaS专栏

《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第二章计算第2节——主流虚拟化技术之VMare ESXi
- 第二章计算第3节——主流虚拟化技术之Xen
- 第二章计算第4节——主流虚拟化技术之KVM
- 第二章计算第5节——商用云主机方案
- 第二章计算第6节——裸金属方案
- 第三章云存储第1节——分布式云存储总述
- 第三章云存储第2节——SPDK方案综述
- 第三章云存储第3节——Ceph统一存储方案
- 第三章云存储第4节——OpenStack Swift 对象存储方案
- 第三章云存储第5节——商用分布式云存储方案
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4节——OSPF协议
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow
1. Linux Namespaces机制简介
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。很早以前的Unix有一个叫chroot的系统调用(通过修改根目录把用户jail到一个特定目录下),chroot提供了一种简单的隔离模式:chroot内部的文件系统无法访问外部的内容。Linux Namespace在此基础上,提供了对UTS、IPC、mount、PID、network、User等系统资源的隔离机制。在此机制下,这些系统资源不再是全局性的,而是属于特定的Namespace。每个Namespace里面的资源对其他Namespace都是透明的。要创建新的Namespace,只需要在调用clone时指定相应的flag。Linux Namespaces机制为实现基于容器的虚拟化技术提供了很好的基础,LXC(Linux containers)就是利用这一特性实现了资源的隔离。不同container内的进程属于不同的Namespace,彼此透明,互不干扰。
命名空间提供了虚拟化的一种轻量级形式,使得我们可以从不同的方面来查看运行系统的全局属性。该机制类似于Solaris中的zone或 FreeBSD中的jail。对该概念做一般概述之后,我将讨论命名空间框架所提供的基础设施。
1.1 概念
传统意义上,在Linux以及其他衍生的UNIX变体中,许多资源是全局管理的,例如,系统中的所有进程按照惯例是通过PID标识的,这意味着内核必须管理一个全局的PID列表。而且,所有调用者通过uname系统调用返回的系统相关信息(包括系统名称和有关内核的一些信息)都是相同的。用户ID的管理方式类似,即各个用户是通过一个全局唯一的UID号标识。
全局ID使得内核可以有选择地允许或拒绝某些特权。虽然UID为0的root用户基本上允许做任何事,但其他用户ID则会受到限制。例如UID为n 的用户,不允许杀死属于用户m的进程(m≠ n)。但这不能防止用户看到彼此,即用户n可以看到另一个用户m也在计算机上活动。通常情况下,只要用户只能操纵他们自己的进程,这就没什么问题,因为没有理由不允许用户看到其他用户的进程。
但有些情况下,这种效果可能是不想要的。如果提供Web主机的供应商打算向用户提供Linux计算机的全部访问权限,包括root权限在内。传统上,这需要为每个用户准备一台计算机,代价太高。使用KVM或VMWare提供的虚拟化环境是一种解决问题的方法,但资源分配做得不是非常好。计算机的各个用户都需要一个独立的内核,以及一份完全安装好的配套的用户层应用。
命名空间提供了一种不同的解决方案,所需资源较少。在虚拟化的系统中,一台物理计算机可以运行多个内核,可能是并行的多个不同的操作系统。而命名空间则只使用一个内核在一台物理计算机上运作,前述的所有全局资源都通过命名空间抽象起来。这使得可以将一组进程放置到容器中,各个容器彼此隔离。隔离可以使容器的成员与其他容器毫无关系。但也可以通过允许容器进行一定的共享,来降低容器之间的分隔。例如,容器可以设置为使用自身的PID集合,但仍然与其他容器共享部分文件系统。
本质上,命名空间建立了系统的不同视图。此前的每一项全局资源都必须包装到容器数据结构中,只有资源和包含资源的命名空间构成的二元组仍然是全局唯一的。虽然在给定容器内部资源是自足的,但无法提供在容器外部具有唯一性的ID。
考虑系统上有3个不同命名空间的情况。命名空间可以组织为层次,一个命名空间是父命名空间,衍生了两个子命名空间。假定容器用于虚拟主机配置中,其中的每个容器必须看起来像是单独的一台Linux计算机。因此其中每一个都有自身的init进程,PID为0,其他进程的PID 以递增次序分配。两个子命名空间都有PID为0的init进程,以及PID分别为2和3的两个进程。由于相同的PID在系统中出现多次,PID号不是全局唯一的。
虽然子容器不了解系统中的其他容器,但父容器知道子命名空间的存在,也可以看到其中执行的所有进程。子容器的进程映射到父容器中,PID为4到 9。尽管系统上有9个进程,但却需要15个PID来表示,因为一个进程可以关联到多个PID。至于哪个PID是"正确"的,则依赖于具体的上下文。
如果命名空间包含的是比较简单的量,也可以是非层次的,例如UTS命名空间。在这种情况下,父子命名空间之间没有联系。
请注意,Linux系统对简单形式的命名空间的支持已经有很长一段时间了,主要是chroot系统调用。该方法可以将进程限制到文件系统的某一部分,因而是一种简单的命名空间机制。但真正的命名空间能够控制的功能远远超过文件系统视图。
新的命名空间可以用下面两种方法创建。
(1) 在用fork或clone系统调用创建新进程时,有特定的选项可以控制是与父进程共享命名空间,还是建立新的命名空间。
(2) unshare系统调用将进程的某些部分从父进程分离,其中也包括命名空间。更多信息请参见手册页unshare(2)。
在进程已经使用上述的两种机制之一从父进程命名空间分离后,从该进程的角度来看,改变全局属性不会传播到父进程命名空间,而父进程的修改也不会传播到子进 程,至少对于简单的量是这样。而对于文件系统来说,情况就比较复杂,其中的共享机制非常强大,带来了大量的可能性。在标准内核中命名空间当前仍然标记为试 验性的,为使内核的所有部分都能够感知到命名空间,相关开发仍然在进行中。但就内核版本2.6.24而言,基本的框架已经建立就绪。 当前的实现仍然存在一些问题,相关的信息可以参见Documentation/namespaces/compatibility-list.txt文件。
1.2 发展历程
我们先来看看它的发展历程。

namespace 的历史过程
1.2.1 最早期 - Plan 9
namespace 的早期提出及使用要追溯到 Plan 9 from Bell Labs ,贝尔实验室的 Plan 9。这是一个分布式操作系统,由贝尔实验室的计算科学研究中心在八几年至02年开发的(02年发布了稳定的第四版,距离92年发布的第一个公开版本已10年打磨),现在仍然被操作系统的研究者和爱好者开发使用。在 Plan 9 的设计与实现中,我们着重提以下3点内容:
- 文件系统:所有系统资源都列在文件系统中,以 Node 标识。所有的接口也作为文件系统的一部分呈现。
- Namespace:能更好的应用及展示文件系统的层次结构,它实现了所谓的 “分离”和“独立”。
- 标准通信协议:9P协议(Styx/9P2000)。
1.2.2 开始加入 Linux Kernel
Namespace 开始进入 Linux Kernel 的版本是在 2.4.X,最初始于 2.4.19 版本。但是,自 2.4.2 版本才开始实现每个进程的 namespace。

Linux Kernel Note

Linux Kernel 对应的各操作系统版本
1.2.3 Linux 3.8 基本实现
Linux 3.8 中终于完全实现了 User Namespace 的相关功能集成到内核。这样 Docker 及其他容器技术所用到的 namespace 相关的能力就基本都实现了。
 Linux Kernel 从 2001 到2013 逐步演变,完成了 namespace 的实现
Linux Kernel 从 2001 到2013 逐步演变,完成了 namespace 的实现
2 Namespaces分类
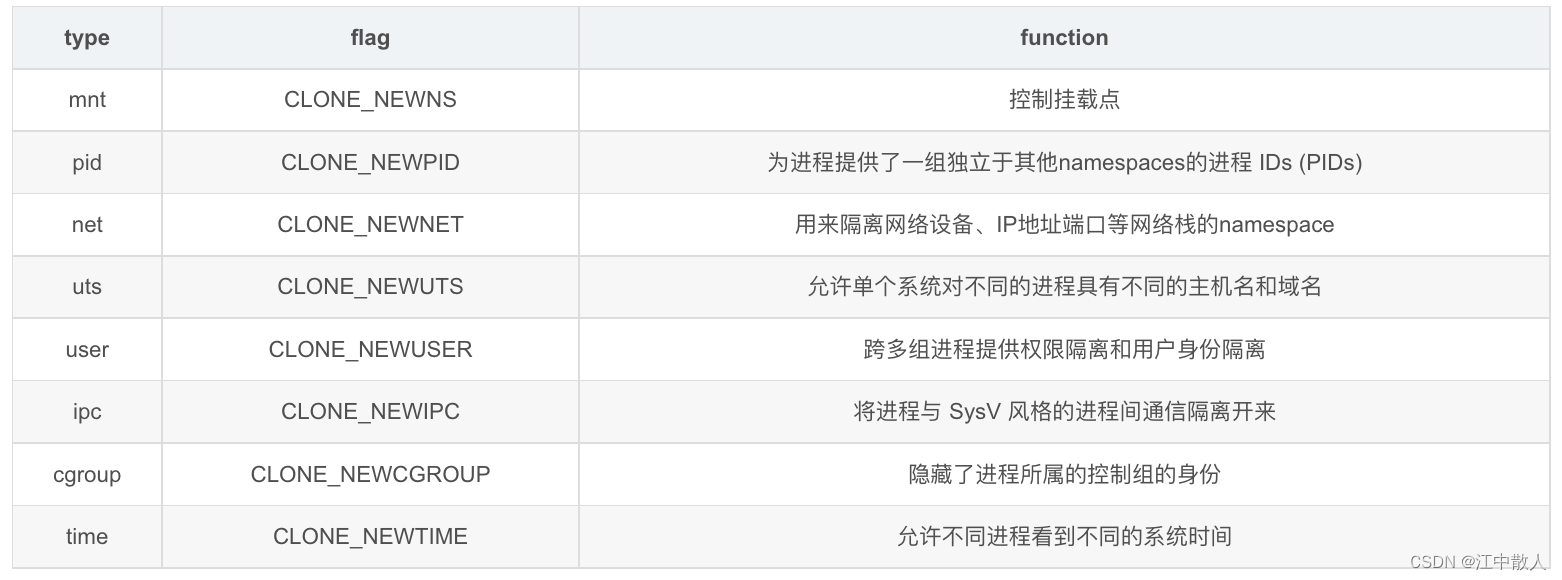
截至至内核5.6,namespaces一共有8种。各个类型的namespace作用方式都是一样的:每个进程都和一个namespace相关联,而且只能看到或使用由这个namespace和它可用的子代namespaces所关联的资源,通过这种方法,每个进程对系统资源都有一个不同的视角。哪种资源被隔离取决于为给定进程组创建的namespace类型。

namespace类型
2.1 PID Namespace
我们知道在 Linux 系统中,每个进程都会有自己的独立的 PID,而 PID namespace 主要是用于隔离进程号。即,在不同的 PID namespace 中可以包含相同的进程号。每个 PID namespace 中进程号都是从 1 开始的,在此 PID namespace 中可通过调用 fork(2), vfork(2)和 clone(2) 等系统调用来创建其他拥有独立 PID 的进程。要使用 PID namespace 需要内核支持 CONFIG_PID_NS 选项。如下:
(MoeLove) ➜ grep CONFIG_PID_NS /boot/config-$(uname -r)
CONFIG_PID_NS=y
init 进程
我们都知道在 Linux 系统中有一个进程比较特殊,所谓的 init 进程,也就是 PID 为 1 的进程。前面我们已经说了每个 PID namespace 中进程号都是从 1 开始的,那么它有什么特点呢?
首先,PID namespace 中的 1 号进程是所有孤立进程的父进程。
其次,如果这个进程被终止,内核将调用 SIGKILL 发出终止此 namespace 中的所有进程的信号。这部分内容与 Kubernetes 中应用的优雅关闭/平滑升级等都有一定的联系。(对此部分感兴趣的小伙伴可以留言交流,如果对这些内容感兴趣的话,我可以专门写一篇展开来聊)
最后,从 Linux v3.4 内核版本开始,如果在一个 PID namespace 中发生 reboot() 的系统调用,则 PID namespace 中的 init 进程会立即退出。这算是一个比较特殊的技巧,可用于处理高负载机器上容器退出的问题。
PID namespace 的层次结构
PID namespace 支持嵌套,除了初始的 PID namespace外,其余的 PID namespace 都拥有其父节点的 PID namespace。也就是说 PID namespace 也是树形结构的,此结构内的所有 PID namespace 我们都可以追踪到祖先 PID namespace。当然,这个深度也不是无限的,从 Linux v3.7 内核版本开始,树的最大深度被限制成 32 。
如果达到此最大深度,将会抛出 No space left on device的错误。(我之前尝试嵌套容器的时候遇到过)
在同一个(且同级) PID namespace 中,进程间彼此可见。
但如果某个进程位于子 PID namespace 的话,那么该进程是看不到上一层(即,父 PID namespace)中的进程的。进程间是否可见,决定了进程间能否存在一定的关联和调用关系,小伙伴们对这个应该比较熟悉,这里我就不赘述了。
那么,进程是否可以调度到不同层级的 PID namespace 呢?
我们先来说结论,进程在 PID namespace 中的调度只能是单向调度(从高 -> 低)。即:
- 进程只能从父 PID namespace 调度到 子 PID namespace 中;
- 进程不能从子 PID namespace 调度到 父 PID namespace 中;
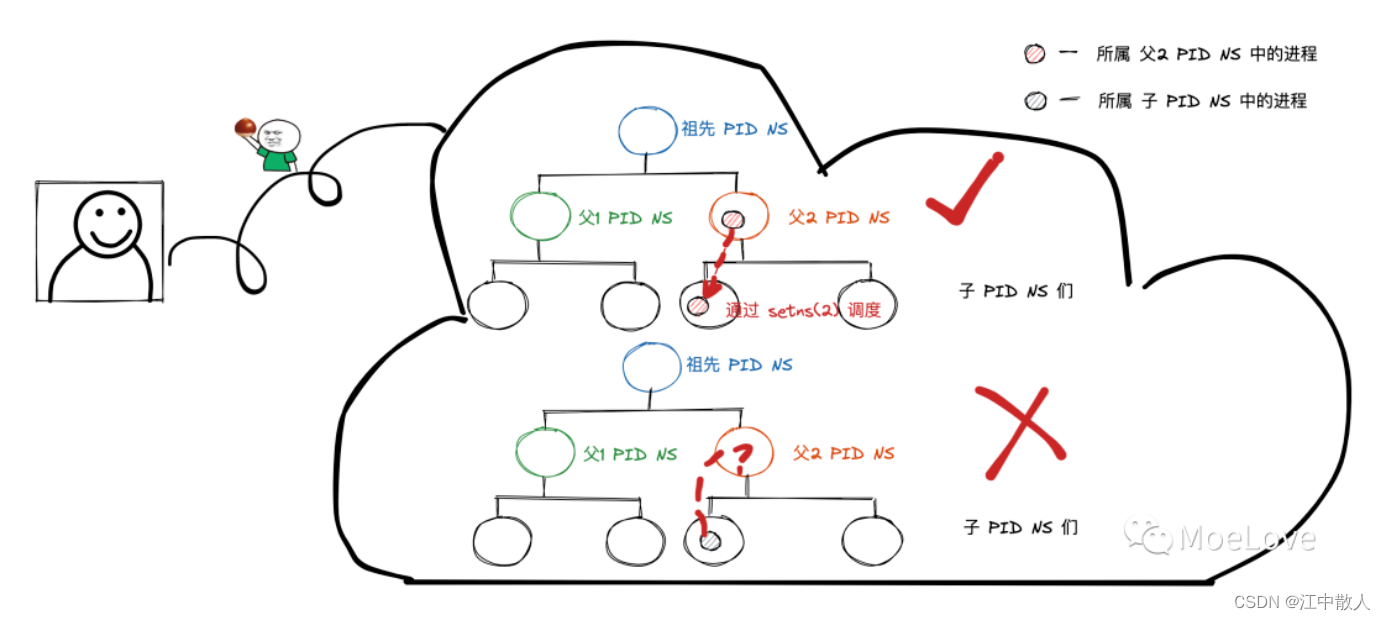
通过 setns(2) 调度进程说明
PID namespace 的层级关系其实是由 ioctl_ns(2) 系统调用进行发现和维护的(NS_GET_PARENT),这里先不展开。那么,上述内容中的调度是如何实现的呢?
要解答这个问题,就必须先意识到在 PID namespace 创建之初,哪些进程具备该 namespace 的权限就已经确定了。至于调度,我们可以简单地将其理解成关系映射或者符号链接。
线程必须在同一个PID namespace 中,以便保证进程中的线程间可以彼此互传信号。这就导致了CLONE_NEWPID 不能与 CLONE_THREAD 同时使用。但如果分布在不同 PID namespace 的多个进程互相有信号传递的需求要怎么办呢?用共享的信号队列即可解决。
此外,我们常接触到的 /proc 目录下有很多 /proc/${PID}的目录,在其中可看到 PID namespace 中的进程情况。同时此目录也是可直接通过挂载方式进行操作的。比如:
(MoeLove) ➜ mount |grep proc
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
有没有办法知道当前最大的 PID 数呢?
这也是可以的,自从 Linux v3.3 版本的内核开始新增了一个 /proc/sys/kernel/ns_last_pid的文件,用于记录最后一个进程的 ID 。
当需要分配下一个进程 ID 的时候,内核会去搜索最大的未使用 ID 进行分配,随后会更新此文件中 PID 的信息。
实现
当调用clone时,设定了CLONE_NEWPID,就会创建一个新的PID Namespace,clone出来的新进程将成为Namespace里的第一个进程。一个PID Namespace为进程提供了一个独立的PID环境,PID Namespace内的PID将从1开始,在Namespace内调用fork,vfork或clone都将产生一个在该Namespace内独立的PID。新创建的Namespace里的第一个进程在该Namespace内的PID将为1,就像一个独立的系统里的init进程一样。该Namespace内的孤儿进程都将以该进程为父进程,当该进程被结束时,该Namespace内所有的进程都会被结束。PID Namespace是层次性,新创建的Namespace将会是创建该Namespace的进程属于的Namespace的子Namespace。子Namespace中的进程对于父Namespace是可见的,一个进程将拥有不止一个PID,而是在所在的Namespace以及所有直系祖先Namespace中都将有一个PID。系统启动时,内核将创建一个默认的PID Namespace,该Namespace是所有以后创建的Namespace的祖先,因此系统所有的进程在该Namespace都是可见的。
2.2 IPC Namespace
IPC namespaces 隔离了 IPC 资源,如 System V IPC objects、 POSIX message queues。每个 IPC namespace 都有着自己的一组 System V IPC 标识符,以及 POSIX 消息队列系统。在一个 IPC namespace 中创建的对象,对所有该 namespace 下的成员均可见(对其他 namespace 下的成员均不可见)。
使用 IPC namespace 需要内核支持 CONFIG_IPC_NS 选项。如下:
(MoeLove) ➜ grep CONFIG_IPC_NS /boot/config-$(uname -r)
CONFIG_IPC_NS=y
可以在 IPC namespace 中设置以下 /proc 接口:
- /proc/sys/fs/mqueue - POSIX 消息队列接口
- /proc/sys/kernel - System V IPC 接口 (msgmax, msgmnb, msgmni, sem, shmall, shmmax, shmmni, shm_rmid_forced)
- /proc/sysvipc - System V IPC 接口
当 IPC namespace 被销毁时(空间里的最后一个进程都被停止删除时),在 IPC namespace 中创建的 object 也会被销毁。
实现
当调用clone时,设定了CLONE_NEWIPC,就会创建一个新的IPC Namespace,clone出来的进程将成为Namespace里的第一个进程。一个IPC Namespace有一组System V IPC objects 标识符构成,这标识符有IPC相关的系统调用创建。在一个IPC Namespace里面创建的IPC object对该Namespace内的所有进程可见,但是对其他Namespace不可见,这样就使得不同Namespace之间的进程不能直接通信,就像是在不同的系统里一样。当一个IPC Namespace被销毁,该Namespace内的所有IPC object会被内核自动销毁。
PID Namespace和IPC Namespace可以组合起来一起使用,只需在调用clone时,同时指定CLONE_NEWPID和CLONE_NEWIPC,这样新创建的Namespace既是一个独立的PID空间又是一个独立的IPC空间。不同Namespace的进程彼此不可见,也不能互相通信,这样就实现了进程间的隔离。
2.3 mount Namespace
Mount namespaces 最早出现在 Linux 2.4.19 版本。Mount namespaces 隔离了各空间中挂载的进程实例。每个 mount namespace 的实例下的进程会看到不同的目录层次结构。每个进程在 mount namespace 中的描述可以在下面的文件视图中看到:
- /proc/[pid]/mounts
- /proc/[pid]/mountinfo
- /proc/[pid]/mountstats
一个新的 Mount namespace 的创建标识是 CLONE_NEWNS ,使用了 clone(2) 或者 unshare(2) 。
- 如果 Mount namespace 用 clone(2) 创建,子 namespace 的挂载列表是从父进程的 mount namespace 拷贝的。
- 如果 Mount namespace 用 unshare(2) 创建,新 namespace 的挂载列表是从调用者之前的 moun namespace 拷贝的。
如果 mount namespace 发生了修改,会引起什么样的连锁反应?下面,我们就在 共享子树中谈谈。
每个 mount 都被可以有如下标记 :
- MS_SHARED - 与组内每个成员分享 events 。也就是说相同的 mount 或者 unmount 将自动发生在组内其他的 mounts 中。反之,mount 或者 unmount 事件 也会影响这次的 event 动作。
- MS_PRIVATE - 这个 mount 是私有的。mount 或者 unmount events 都不会影响这次的 event 动作。
- MS_SLAVE - mount 或者 unmount events 会从 master 节点传入影响该节点。但是这个节点下的 mount 或者 unmount events 不会影响组内的其他节点。
- MS_UNBINDABLE - 这也是个私有的 mount 。任何尝试绑定的 mount 在这个设置下都将失败。
在文件 /proc/[pid]/mountinfo 中可以看到 propagation 类型的字段。每个对等组都会由内核生成唯一的 ID ,同一对等组的 mount 都是这个 ID(即,下文中的 X )。
(MoeLove) ➜ cat /proc/self/mountinfo |grep root 65 1 0:33 /root / rw,relatime shared:1 - btrfs /dev/nvme0n1p6 rw,seclabel,compress=zstd:1,ssd,space_cache,subvolid=256,subvol=/root 1210 65 0:33 /root/var/lib/docker/btrfs /var/lib/docker/btrfs rw,relatime shared:1 - btrfs /dev/nvme0n1p6 rw,seclabel,compress=zstd:1,ssd,space_cache,subvolid=256,subvol=/root
- shared:X - 在组 X 中共享。
- master:X - 对于组 X 而言是 slave,即,从属于 ID 为 X 的主。
- propagate_from:X - 接收从组 X 发出的共享 mount。这个标签总是个 master:X 一同出现。
- unbindable - 表示不能被绑定,即,不与其他关联从属。
新 mount namespace 的传播类型取决于它的父节点。如果父节点的传播类型是 MS_SHARED ,那么新 mount namespace 的传播类型是 MS_SHARED ,不然会默认为 MS_PRIVATE。
关于 mount namespaces 我们还需要注意以下几点:
(1)每个 mount namespace 都有一个 owner user namespace。如果新的 mount namespace 和拷贝的 mount namespace 分属于不同的 user namespace ,那么,新的 mount namespace 优先级低。
(2)当创建的 mount namespace 优先级低时,那么,slave 的 mount events 会优先于 shared 的 mount events。
(3)高优先级和低优先级的 mount namespace 有关联被锁定在一起时,他们都不能被单独卸载。
(4)mount(2) 标识和 atime 标识会被锁定,即,不能被传播影响而修改。
Mount namespace用来控制挂载点。不同namespace中的进程看到的文件系统层次也是不一样的。在mount namespace中调用mount(), unmount()只会影响当前namespace内的文件系统。在创建时,当前mount namespace中的挂载点被复制到新命名空间,但之后创建的挂载点不会在namespaces之间传播(如果使用共享子树,可以在命名空间之间传播挂载点 )。
用于创建这种类型的新命名空间的clone flag是 CLONE_NEWNS - “NEW NameSpace”的缩写。 这个术语不是描述性的(无法从名字看出要创建哪种命名空间),因为挂载命名空间是第一种命名空间,设计人员没有预料到还有其他命名空间。
实现
当调用clone时,设定了CLONE_NEWNS,就会创建一个新的mount Namespace。每个进程都存在于一个mount Namespace里面,mount Namespace为进程提供了一个文件层次视图。如果不设定这个flag,子进程和父进程将共享一个mount Namespace,其后子进程调用mount或umount将会影响到所有该Namespace内的进程。如果子进程在一个独立的mount Namespace里面,就可以调用mount或umount建立一份新的文件层次视图。该flag配合pivot_root系统调用,可以为进程创建一个独立的目录空间。
2.4 Network Namespace
Network namespaces 隔离了与网络相关的系统资源(这里罗列一些):
- network devices - 网络设备
- IPv4 and IPv6 protocol stacks - IPv4、IPv6 的协议栈
- IP routing tables - IP 路由表
- firewall rules - 防火墙规则
- /proc/net (即 /proc/PID/net)
- /sys/class/net
- /proc/sys/net 目录下的文件
- 端口、socket
- UNIX domain abstract socket namespace
使用 Network namespaces 需要内核支持 CONFIG_NET_NS 选项。如下:
(MoeLove) ➜ grep CONFIG_NET_NS /boot/config-$(uname -r)
CONFIG_NET_NS=y
一个物理网络设备只能存在于一个 Network namespace 中。当一个 Network namespace 被释放时(空间里的最后一个进程都被停止删除时),物理网络设备将被移动到初始的 Network namespace 而不是上层的 Network namespace。
一个虚拟的网络设备(veth(4)) ,在 Network namespace 间通过一个类似管道的方式进行连接。这使得它能存在于多个 Network namespace,但是,当 Network namespace 被摧毁时,该空间下包含的 veth(4) 设备可能被破坏。
实现
当调用clone时,设定了CLONE_NEWNET,就会创建一个新的Network Namespace。一个Network Namespace为进程提供了一个完全独立的网络协议栈的视图。包括网络设备接口,IPv4和IPv6协议栈,IP路由表,防火墙规则,sockets等等。一个Network Namespace提供了一份独立的网络环境,就跟一个独立的系统一样。一个物理设备只能存在于一个Network Namespace中,可以从一个Namespace移动另一个Namespace中。虚拟网络设备(virtual network device)提供了一种类似管道的抽象,可以在不同的Namespace之间建立隧道。利用虚拟化网络设备,可以建立到其他Namespace中的物理设备的桥接。当一个Network Namespace被销毁时,物理设备会被自动移回init Network Namespace,即系统最开始的Namespace。
2.5 UTS Namespace
UTS namespaces 隔离了主机名和 NIS 域名。使用 UTS namespaces 需要内核支持 CONFIG_UTS_NS 选项。如:
(MoeLove) ➜ grep CONFIG_UTS_NS /boot/config-$(uname -r)
CONFIG_UTS_NS=y
在同一个 UTS namespace 中,通过 sethostname(2) 和 and setdomainname(2) 系统调用进行的设置和修改是所有进程共享查看的,但是对于不同 UTS namespaces 而言,则彼此隔离不可见。
实现
当调用clone时,设定了CLONE_NEWUTS,就会创建一个新的UTS Namespace。一个UTS Namespace就是一组被uname返回的标识符。新的UTS Namespace中的标识符通过复制调用进程所属的Namespace的标识符来初始化。Clone出来的进程可以通过相关系统调用改变这些标识符,比如调用sethostname来改变该Namespace的hostname。这一改变对该Namespace内的所有进程可见。CLONE_NEWUTS和CLONE_NEWNET一起使用,可以虚拟出一个有独立主机名和网络空间的环境,就跟网络上一台独立的主机一样。
2.6 Cgroup Namespace
Cgroup namespace 是进程的 cgroups 的虚拟化视图,通过 /proc/[pid]/cgroup 和 /proc/[pid]/mountinfo 展示。使用 cgroup namespace 需要内核开启 CONFIG_CGROUPS 选项。可通过以下方式验证:
(MoeLove) ➜ grep CONFIG_CGROUPS /boot/config-$(uname -r)
CONFIG_CGROUPS=y
cgroup namespace 提供的了一系列的隔离支持:
- 防止信息泄漏(容器不应该看到容器外的任何信息)。
- 简化了容器迁移。
- 限制容器进程资源,因为它会把 cgroup 文件系统进行挂载,使得容器进程无法获取上层的访问权限。
每个 cgroup namespace 都有自己的一组 cgroup 根目录。这些 cgroup 的根目录是在 /proc/[pid]/cgroup 文件中对应记录的相对位置的基点。当一个进程用 CLONE_NEWCGROUP(clone(2) 或者 unshare(2)) 创建一个新的 cgroup namespace时,它当前的 cgroups 的目录就变成了新 namespace 的 cgroup 根目录。
(MoeLove) ➜ cat /proc/self/cgroup
0::/user.slice/user-1000.slice/session-2.scope
当一个目标进程从 /proc/[pid]/cgroup 中读取 cgroup 关系时,每个记录的路径名会在第三字段中展示,会关联到正在读取的进程的相关 cgroup 分层结构的根目录。如果目标进程的 cgroup 目录位于正在读取的进程的 cgroup namespace 根目录之外时,那么,路径名称将会对每个 cgroup 层次中的上层节点显示 ../ 。
我们来看看下面的示例(这里以 cgroup v1 为例,如果你想看 v2 版本的示例,请在留言中告诉我):
1. 在初始的 cgroup namespace 中,我们使用 root (或者有 root 权限的用户),在 freezer 层下创建一个子 cgroup 名为 moelove-sub,同时,将进程放入该 cgroup 进行限制。
(MoeLove) ➜ mkdir -p /sys/fs/cgroup/freezer/moelove-sub
(MoeLove) ➜ sleep 6666666 & [1] 1489125
(MoeLove) ➜ echo 1489125 > /sys/fs/cgroup/freezer/moelove-sub/cgroup.procs
2. 我们在 freezer 层下创建另外一个子 cgroup,名为 moelove-sub2, 并且再放入执行进程号。可以看到当前的进程已经纳入到 moelove-sub2的 cgroup 下管理了。
(MoeLove) ➜ mkdir -p /sys/fs/cgroup/freezer/moelove-sub2
(MoeLove) ➜ echo $$ 1488899
(MoeLove) ➜ echo 1488899 > /sys/fs/cgroup/freezer/moelove-sub2/cgroup.procs
(MoeLove) ➜ cat /proc/self/cgroup |grep freezer 7:freezer:/moelove-sub2
3. 我们使用 unshare(1) 创建一个进程,这里使用了 -C参数表示是新的 cgroup namespace, 使用了 -m参数表示是新的 mount namespace。
(MoeLove) ➜ unshare -Cm bash
root@moelove:~#
4. 从用 unshare(1) 启动的新 shell 中,我们可以在 /proc/[pid]/cgroup 文件中看到,新 shell 和以上示例中的进程:
root@moelove:~# cat /proc/self/cgroup | grep freezer
7:freezer:/
root@moelove:~# cat /proc/1/cgroup | grep freezer
7:freezer:/..
# 第一个示例进程
root@moelove:~# cat /proc/1489125/cgroup | grep freezer
7:freezer:/../moelove-sub
5. 从上面的示例中,我们可以看到新 shell 的 freezer cgroup 关系中,当新的 cgroup namespace 创建时,freezer cgroup 的根目录与它的关系也就建立了。
root@moelove:~# cat /proc/self/mountinfo | grep freezer
1238 1230 0:37 /.. /sys/fs/cgroup/freezer rw,nosuid,nodev,noexec,relatime - cgroup cgroup rw,freezer
6. 第四个字段 ( /..) 显示了在 cgroup 文件系统中的挂载目录。从 cgroup namespaces 的定义中,我们可以知道,进程当前的 freezer cgroup 目录变成了它的根目录,所以这个字段显示 /.. 。我们可以重新挂载来处理它。
root@moelove:~# mount --make-rslave /
root@moelove:~# umount /sys/fs/cgroup/freezer
root@moelove:~# mount -t cgroup -o freezer freezer /sys/fs/cgroup/freezer
root@moelove:~# cat /proc/self/mountinfo | grep freezer
1238 1230 0:37 / /sys/fs/cgroup/freezer rw,relatime - cgroup freezer rw,freezer
root@moelove:~# mount |grep freezer
freezer on /sys/fs/cgroup/freezer type cgroup (rw,relatime,freezer)
2.7 Time Namespace
在聊 time namespace 之前,我们需要先聊下单调时间。首先,我们通常提到的系统时间,指的是 clock realtime,即,机器对当前时间的展示。它可以向前或者向后调整(结合 NTP 服务来理解)。而 clock monotonic 表示在某一时刻之后的时间记录,它是单向向后的绝对时间,不受系统时间的变化所影响。
使用 time namespace 需要内核支持 CONFIG_TIME_NS 选项。如:
(MoeLove) ➜ grep CONFIG_TIME_NS /boot/config-$(uname -r)
CONFIG_TIME_NS=y
time namespace 不会虚拟化 CLOCK_REALTIME 时钟。你可能会好奇,为什么内核支持 time namespace 呢?主要是为了一些特殊的场景。
time namespace 中的所有进程共享由 time namespace 提供的以下两个参数:
- CLOCK_MONOTONIC - 单调时间,一个不可设置的时钟;
- CLOCK_BOOTTIME(可参考 CLOCK_BOOTTIME_ALARM 内核参数)- 不可设置的时钟,包括系统暂停的时间。
time namespace 目前只能使用 CLONE_NEWTIME 标识,通过调用 unshare(2) 系统调用进行创建。创建 time namespace 的进程是独立于新建的 time namespace 之外的,而该进程后续的子进程将会被放置到新建的 time namespace 之内。同一个 time namespace 中的进程们会共享 CLOCK_MONOTONIC 和 CLOCK_BOOTTIME。
当父进程创建子进程时,子进程的 time namespace 归属将在文件 /proc/[pid]/ns/time_for_children 中显示。
(MoeLove) ➜ ls -al /proc/self/ns/time_for_children
lrwxrwxrwx. 1 tao tao 0 12月 14 02:06 /proc/self/ns/time_for_children -> 'time:[4026531834]'
文件 /proc/PID/timens_offsets 定义了初始 time namespace 的单调时钟和启动时钟,并记录了偏移量。(如果一个新的 time namespace 还没有进程入驻时,是可以进行修改的。这里暂不展开,感兴趣的小伙伴可讨论区留言交流讨论。)
需要注意的是:在初始的 time namespace 中,/proc/self/timens_offsets 显示的偏移量都为 0。
(MoeLove) ➜ cat /proc/self/timens_offsets
monotonic 0 0
boottime 0 0
其中第二列和第三列的含义如下:
- 可以为负值,单位 :秒(s)
- 是个无符号值,单位 :纳秒(ns)
以下的时钟接口都与此 namespace 有所关联:
- clock_gettime(2)
- clock_nanosleep(2)
- nanosleep(2)
- timer_settime(2)
- timerfd_settime(2)
整体而言, time namespace 在一些特殊场景下还是很有用的。
2.8 User Namespace
User namespaces 顾名思义是隔离了用户 id、组 id 等。使用 user namespaces 需要内核支持 CONFIG_USER_NS 选项。如:
➜ local_time grep CONFIG_USER_NS /boot/config-$(uname -r)
CONFIG_USER_NS=y
进程的用户 id 和组 id 在一个 user namespace 内和外有可能是不同的。比如,一个进程在 user namespace 中的用户和组可以是特权用户(root),但在该 user namespace 之外,可能只是一个普通的非特权用户。这就涉及到用户、组映射(uid_map 、gid_map)等相关的内容了。
自 Linux v3.5 版本的内核开始,在 /proc/[pid]/uid_map 和 /proc/[pid]/gid_map 文件中,我们可以查看到映射内容。
(MoeLove) ➜ cat /proc/self/uid_map
0 0 4294967295
(MoeLove) ➜ cat /proc/self/gid_map
0 0 4294967295
user namespace 也支持嵌套,使用 CLONE_NEWUSER 标识,使用 unshare(2) 或者 clone(2) 等系统调用来创建,最大的嵌套层级深度也是 32。
如果是通过 fork(2) 或者 clone(2) 创建的子进程没带有 CLONE_NEWUSER 标识,也是一样的,子进程跟父进程同在一个 user namespace 中。树状的关联关系同样通过 ioctl(2) 系统调用接口维护。
一个单线程进程可以通过 setns(2) 系统调用来调整其归属的 user namespace。
此外, user namespace 还有个很重要的规则,那就是关于 Linux capability 的继承关系。关于 Linux capability 我就不展开了,这里简单记录一下:
- 当进程所在的 user namespace 拥有 effective capability set 中的 capability 时,该进程具有该 capability。
- 当进程在该 user namespace 中拥有 capability 时,该进程在此 user namespace 的所有子 user namespace 中都拥有该 capability。
- 创建该 user namespace 的用户会被内核记录为 owner ,即,拥有该 user namespace 中的全部 capabilities。
对于 Docker 而言,它可以原生的支持此能力,进而达到对容器环境的一种保护。
3 理解Linux namespace
用户可以创建指定类型的namespace并将程序放入该namespace中运行,这表示从当前的系统运行环境中隔离一个进程的运行环境,在此namespace中运行的进程将认为自己享有该namespace中的独立资源。
实际上,即使用户没有手动创建Linux namespace,Linux系统开机后也会创建一个默认的namespace,称为「root namespace」,所有进程默认都运行在root namespace中,每个进程都认为自己拥有该namespace中的所有系统全局资源。
回顾一下Linux的开机启动流程,内核加载成功后将初始化系统运行环境,这个运行环境就是root namespace环境,系统运行环境初始化完成后,便可以认为操作系统已经开始工作了。
「每一个namespace都基于当前内核」,无论是默认的root namespace还是用户创建的每一个namespace,都基于当前内核工作。所以可以认为namespace是内核加载后启动的一个特殊系统环境,用户进程可以在此环境中独立享用资源。更严格地说,「root namespace直接基于内核,而用户创建的namespace运行环境基于当前所在的namespace」。之所以用户创建的namespace不直接基于内核环境,是因为每一个namespace可能都会修改某些运行时内核参数。
比如,用户创建的uts namespace1中修改了主机名为ns1,然后在namespace1中创建uts namespace2时,namespace2默认「将共享namespace1的其他资源并拷贝namespace1的主机名资源」,因此namespace2的主机名初始时也是ns1。当然,namespace2是隔离的,可以修改其主机名为ns2,这不会影响其他namespace,修改后,将只有namespace2中的进程能看到其主机名为ns2。
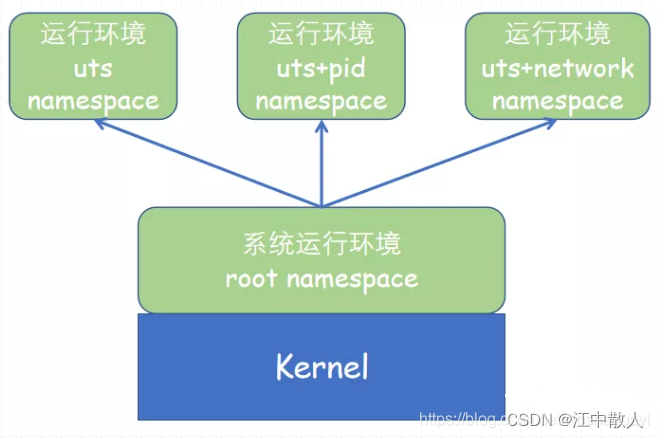
可以通过如下方式查看某个进程运行在哪一个namespace中,即该进程享有的独立资源来自于哪一个namespace。
# ls -l /proc/<PID>/ns
$ ls -l /proc/$$/ns | awk '{print $1,$(NF-2),$(NF-1),$NF}'
lrwxrwxrwx cgroup -> cgroup:[4026531835] lrwxrwxrwx ipc -> ipc:[4026531839] lrwxrwxrwx mnt -> mnt:[4026531840] lrwxrwxrwx net -> net:[4026531992] lrwxrwxrwx pid -> pid:[4026531836] lrwxrwxrwx pid_for_children -> pid:[4026531836] lrwxrwxrwx user -> user:[4026531837] lrwxrwxrwx uts -> uts:[4026531838]
$ sudo ls -l /proc/1/ns | awk '{print $1,$(NF-2),$(NF-1),$NF}'
lrwxrwxrwx cgroup -> cgroup:[4026531835]
lrwxrwxrwx ipc -> ipc:[4026531839]
lrwxrwxrwx mnt -> mnt:[4026531840]
lrwxrwxrwx net -> net:[4026531992]
lrwxrwxrwx pid -> pid:[4026531836]
lrwxrwxrwx pid_for_children -> pid:[4026531836]
lrwxrwxrwx user -> user:[4026531837]
lrwxrwxrwx uts -> uts:[4026531838]
这些文件表示当前进程打开的namespace资源,每一个文件都是一个软链接,所指向的文件是一串格式特殊的名称。冒号后面中括号内的数值表示该namespace的inode。如果不同进程的namespace inode相同,说明这些进程属于同一个namespace。
从结果上来看,每个进程都运行在多个namespace中,且pid=1和pid=$$(当前Shell进程)两个进程的namespace完全一样,说明它们运行在相同的环境下(root namespace)
3.1 Namespace 的生命周期
正常的 namespace 的生命周期与最后一个进程的终止和离开相关。但有一些情况,即使最后一个进程已经退出了,namespace 仍不能被销毁。这里来稍微聊下这些特殊的情况:
- /proc/[pid]/ns/* 中的文件被打开或者 mount ,即使最后一个进程退出,也不能被销毁;
- namespace 存在分层,子 namespace 仍存在 ,即使最后一个进程退出,也不能被销毁;
- 一个 user namespace 拥有一些非 user namespace (比如拥有 PID namespace 等其他的 namespace 存在),即使最后一个进程退出,也不能被销毁;
- 对于 PID namespace 而言,如果与 /proc/[pid]/ns/pid_for_children 存在关联关系时,即使最后一个进程退出,也不能被销毁;
当然除此之外还有一些其他的情况,基本都是存在被占用或未被释放。
参考链接
Docker基础技术:Linux Namespace(上) | 酷 壳 - CoolShell
Docker基础技术:Linux Namespace(下) | 酷 壳 - CoolShell
Linux Namespaces机制_preterhuman_peak的博客-程序员宅基地
干货 | 谈谈Linux Namespace - DockOne.io
《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第二章计算第2节——主流虚拟化技术之VMare ESXi
- 第二章计算第3节——主流虚拟化技术之Xen
- 第二章计算第4节——主流虚拟化技术之KVM
- 第二章计算第5节——商用云主机方案
- 第二章计算第6节——裸金属方案
- 第三章云存储第1节——分布式云存储总述
- 第三章云存储第2节——SPDK方案综述
- 第三章云存储第3节——Ceph统一存储方案
- 第三章云存储第4节——OpenStack Swift 对象存储方案
- 第三章云存储第5节——商用分布式云存储方案
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4节——OSPF协议
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow
智能推荐
分布式光纤传感器的全球与中国市场2022-2028年:技术、参与者、趋势、市场规模及占有率研究报告_预计2026年中国分布式传感器市场规模有多大-程序员宅基地
文章浏览阅读3.2k次。本文研究全球与中国市场分布式光纤传感器的发展现状及未来发展趋势,分别从生产和消费的角度分析分布式光纤传感器的主要生产地区、主要消费地区以及主要的生产商。重点分析全球与中国市场的主要厂商产品特点、产品规格、不同规格产品的价格、产量、产值及全球和中国市场主要生产商的市场份额。主要生产商包括:FISO TechnologiesBrugg KabelSensor HighwayOmnisensAFL GlobalQinetiQ GroupLockheed MartinOSENSA Innovati_预计2026年中国分布式传感器市场规模有多大
07_08 常用组合逻辑电路结构——为IC设计的延时估计铺垫_基4布斯算法代码-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏12次。常用组合逻辑电路结构——为IC设计的延时估计铺垫学习目的:估计模块间的delay,确保写的代码的timing 综合能给到多少HZ,以满足需求!_基4布斯算法代码
OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏5次。OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版
关于美国计算机奥赛USACO,你想知道的都在这_usaco可以多次提交吗-程序员宅基地
文章浏览阅读2.2k次。USACO自1992年举办,到目前为止已经举办了27届,目的是为了帮助美国信息学国家队选拔IOI的队员,目前逐渐发展为全球热门的线上赛事,成为美国大学申请条件下,含金量相当高的官方竞赛。USACO的比赛成绩可以助力计算机专业留学,越来越多的学生进入了康奈尔,麻省理工,普林斯顿,哈佛和耶鲁等大学,这些同学的共同点是他们都参加了美国计算机科学竞赛(USACO),并且取得过非常好的成绩。适合参赛人群USACO适合国内在读学生有意向申请美国大学的或者想锻炼自己编程能力的同学,高三学生也可以参加12月的第_usaco可以多次提交吗
MySQL存储过程和自定义函数_mysql自定义函数和存储过程-程序员宅基地
文章浏览阅读394次。1.1 存储程序1.2 创建存储过程1.3 创建自定义函数1.3.1 示例1.4 自定义函数和存储过程的区别1.5 变量的使用1.6 定义条件和处理程序1.6.1 定义条件1.6.1.1 示例1.6.2 定义处理程序1.6.2.1 示例1.7 光标的使用1.7.1 声明光标1.7.2 打开光标1.7.3 使用光标1.7.4 关闭光标1.8 流程控制的使用1.8.1 IF语句1.8.2 CASE语句1.8.3 LOOP语句1.8.4 LEAVE语句1.8.5 ITERATE语句1.8.6 REPEAT语句。_mysql自定义函数和存储过程
半导体基础知识与PN结_本征半导体电流为0-程序员宅基地
文章浏览阅读188次。半导体二极管——集成电路最小组成单元。_本征半导体电流为0
随便推点
【Unity3d Shader】水面和岩浆效果_unity 岩浆shader-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏18次。游戏水面特效实现方式太多。咱们这边介绍的是一最简单的UV动画(无顶点位移),整个mesh由4个顶点构成。实现了水面效果(左图),不动代码稍微修改下参数和贴图可以实现岩浆效果(右图)。有要思路是1,uv按时间去做正弦波移动2,在1的基础上加个凹凸图混合uv3,在1、2的基础上加个水流方向4,加上对雾效的支持,如没必要请自行删除雾效代码(把包含fog的几行代码删除)S..._unity 岩浆shader
广义线性模型——Logistic回归模型(1)_广义线性回归模型-程序员宅基地
文章浏览阅读5k次。广义线性模型是线性模型的扩展,它通过连接函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。广义线性模型拟合的形式为:其中g(μY)是条件均值的函数(称为连接函数)。另外,你可放松Y为正态分布的假设,改为Y 服从指数分布族中的一种分布即可。设定好连接函数和概率分布后,便可以通过最大似然估计的多次迭代推导出各参数值。在大部分情况下,线性模型就可以通过一系列连续型或类别型预测变量来预测正态分布的响应变量的工作。但是,有时候我们要进行非正态因变量的分析,例如:(1)类别型.._广义线性回归模型
HTML+CSS大作业 环境网页设计与实现(垃圾分类) web前端开发技术 web课程设计 网页规划与设计_垃圾分类网页设计目标怎么写-程序员宅基地
文章浏览阅读69次。环境保护、 保护地球、 校园环保、垃圾分类、绿色家园、等网站的设计与制作。 总结了一些学生网页制作的经验:一般的网页需要融入以下知识点:div+css布局、浮动、定位、高级css、表格、表单及验证、js轮播图、音频 视频 Flash的应用、ul li、下拉导航栏、鼠标划过效果等知识点,网页的风格主题也很全面:如爱好、风景、校园、美食、动漫、游戏、咖啡、音乐、家乡、电影、名人、商城以及个人主页等主题,学生、新手可参考下方页面的布局和设计和HTML源码(有用点赞△) 一套A+的网_垃圾分类网页设计目标怎么写
C# .Net 发布后,把dll全部放在一个文件夹中,让软件目录更整洁_.net dll 全局目录-程序员宅基地
文章浏览阅读614次,点赞7次,收藏11次。之前找到一个修改 exe 中 DLL地址 的方法, 不太好使,虽然能正确启动, 但无法改变 exe 的工作目录,这就影响了.Net 中很多获取 exe 执行目录来拼接的地址 ( 相对路径 ),比如 wwwroot 和 代码中相对目录还有一些复制到目录的普通文件 等等,它们的地址都会指向原来 exe 的目录, 而不是自定义的 “lib” 目录,根本原因就是没有修改 exe 的工作目录这次来搞一个启动程序,把 .net 的所有东西都放在一个文件夹,在文件夹同级的目录制作一个 exe._.net dll 全局目录
BRIEF特征点描述算法_breif description calculation 特征点-程序员宅基地
文章浏览阅读1.5k次。本文为转载,原博客地址:http://blog.csdn.net/hujingshuang/article/details/46910259简介 BRIEF是2010年的一篇名为《BRIEF:Binary Robust Independent Elementary Features》的文章中提出,BRIEF是对已检测到的特征点进行描述,它是一种二进制编码的描述子,摈弃了利用区域灰度..._breif description calculation 特征点
房屋租赁管理系统的设计和实现,SpringBoot计算机毕业设计论文_基于spring boot的房屋租赁系统论文-程序员宅基地
文章浏览阅读4.1k次,点赞21次,收藏79次。本文是《基于SpringBoot的房屋租赁管理系统》的配套原创说明文档,可以给应届毕业生提供格式撰写参考,也可以给开发类似系统的朋友们提供功能业务设计思路。_基于spring boot的房屋租赁系统论文