【数据分析】基于RFM模型的线上零售中的客户细分(二):RFM模型实战_零售数据模型有哪些-程序员宅基地
技术标签: 客户细分 RFM模型 同期群分析 数据分析 K-Means # 数据分析及可视化 商业分析 数据挖掘
本系列包含:
基于RFM模型的线上零售中的客户细分(二)
摘要:在上一篇博客《基于RFM模型的线上零售中的客户细分(一):客户细分》中,我们了解了什么是客户细分,这篇博客将会结合具体的商业实例介绍同期群分析、RFM模型,并利用K-Means聚类算法在RFM模型上找到合适的细分集群。
这篇博客详述了RFM模型是如何运用到商业分析中的。篇幅较长,建议分小节阅读。
1.数据处理
下面项目使用的数据集是从UCI机器学习存储库获得的在线零售数据集。
导入需要用到的包。
# Importing standard libraries
import pandas as pd
import numpy as np
import datetime as dt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from matplotlib import pyplot as plt
读入数据。
df = pd.read_excel('OnlineRetail.xlsx',engine='openpyxl')
df.head()

- InvoiceNo: 发票编号。唯一分配给每个交易的6位整数。如果此代码以字母“ c”开头,则表示的是“已取消订单”。
- StockCode: 产品代码。唯一分配给每个不同产品的5位整数。
- Description: 产品描述。
- Quantity: 每笔交易中每个产品的数量。
- InvoiceDate: 发票日期。每笔交易生成的日期和时间。
- UnitPrice: 单价。产品价格,单位为英镑。
- CustomerID: 客户编号。唯一分配给每个客户的5位整数。
- Country: 国家名称。每个客户居住的国家或地区的名称。
df.shape

数据集共有541909条记录。分析之前,需要先删除其中重复的条目。数据包含5268个重复条目(约1%)。
print('Duplicate entries: {}'.format(df.duplicated().sum()))
print('{}% rows are duplicate.'.format(round((df.duplicated().sum()/df.shape[0])*100),2))
df.drop_duplicates(inplace = True)

产品、交易和客户的总数分别与数据集中的产品代码、发票编号和客户ID的总数相对应。
pd.DataFrame([{
'products': len(df['StockCode'].value_counts()),
'transactions': len(df['InvoiceNo'].value_counts()),
'customers': len(df['CustomerID'].value_counts()),
}], columns = ['products', 'transactions', 'customers'], index = ['quantity'])

对于4070种商品,产生了25900个交易。这表明每个商品可能在数据集中存在多个交易。
现在来看一下来自每个国家的订单百分比。
# pandas nunique()用于获取唯一值的统计次数;agg常与groupby连用,用来聚类
temp = df.groupby(['Country'],as_index=False).agg({
'InvoiceNo':'nunique'}).rename(columns = {
'InvoiceNo':'Orders'})
total = temp['Orders'].sum(axis=0)
temp['%Orders'] = round((temp['Orders']/total)*100,4)
temp.head(10)
temp.sort_values(by=['%Orders'],ascending=False,inplace=True)
temp.reset_index(drop=True,inplace=True)
temp.head(10)
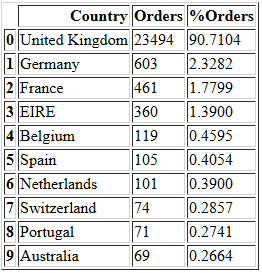
我们选出订单量排名前十的国家。
plt.figure(figsize=(13,6))
splot = sns.barplot(x="Country",y="%Orders",data=temp[:10])
for p in splot.patches:
splot.annotate(format(p.get_height(), '.1f'), #显示的文本
(p.get_x() + p.get_width() / 2., p.get_height()), #x,y的坐标位置
ha = 'center', va = 'center', #注释的坐标以注释框正中心为准
xytext = (0, 9), #注释内容的位置
textcoords = 'offset points') #文本的坐标,offset points表示相对xy偏移的点数
plt.xlabel("Country", size=14)
plt.ylabel("%Orders", size=14)
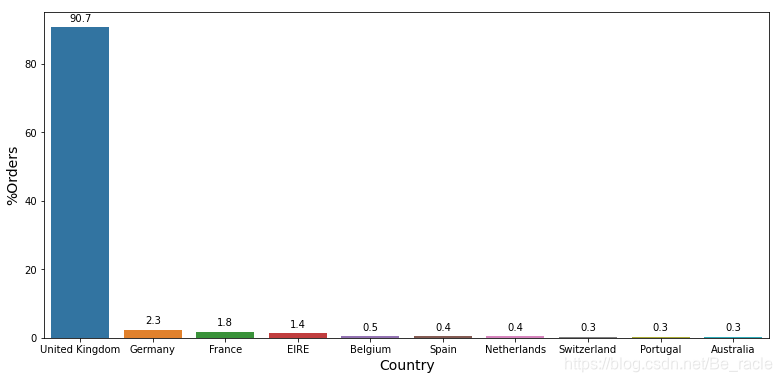
上图显示了来自前10个国家的订单百分比,按订单数量排序。这表明超过90%的订单来自英国,甚至没有订单占3%的其他国家。因此,出于分析目的,我们仅分析来自英国的订单数据。
根据数据,如果发票编号代码以字母“C”开头,则表示已取消订单。我们需要删去这部分数据。现在先来看看这部分数据有多少。
invoices = df['InvoiceNo']
x = invoices.str.contains('C', regex=True) # regex用于正则匹配
x.fillna(0, inplace=True) # NaN的地方用0填充
x = x.astype(int) # 转成布尔类型
x.value_counts()

创建一个标志列以指示该订单是否对应于已取消的订单。
df['order_canceled'] = x
df.head()

df['order_canceled'].value_counts()

n1 = df['order_canceled'].value_counts()[1]
n2 = df.shape[0]
print('Number of orders canceled: {}/{} ({:.2f}%) '.format(n1, n2, n1/n2*100))
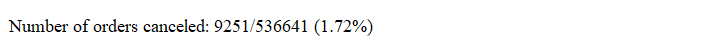
所有已取消的订单的数量都是负数,因此要从数据中删除。最后,再进行检查,以确认在未取消的订单中是否有负数量的订单。此类数据有1336条。
df = df.loc[df['order_canceled'] == 0,:] # 0表示没有取消
df.reset_index(drop=True,inplace=True)
df.loc[df['Quantity'] < 0,:] # 所有 Quantity < 0 的行
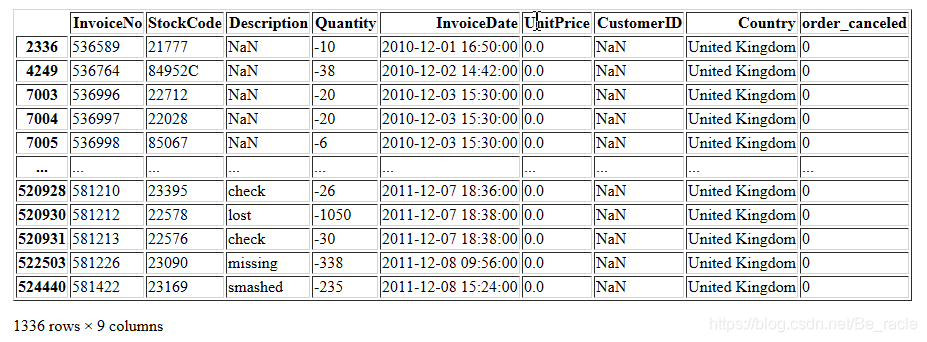
从上图可以看出,这些情况是CustomerID值为NaN的情况。这些数据也要从数据集中删除。
df = df[df['CustomerID'].notna()]
df.set_index(drop=True,inplace=True)
现在,将数据过滤为仅包含来自英国的订单,最后,通过调用info()方法检查数据的结构。
df_uk = df[df.Country == 'United Kingdom']
df_uk.head()

df_uk.info()

数据中的任何列中都没有空值,并且数据总共349227行。
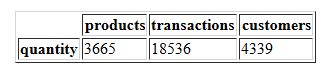
现在,在过滤后的数据集中再次检查商品、交易和客户的数量。
pd.DataFrame([{
'products': len(df['StockCode'].value_counts()),
'transactions': len(df['InvoiceNo'].value_counts()),
'customers': len(df['CustomerID'].value_counts()),
}], columns = ['products', 'transactions', 'customers'], index = ['quantity'])
2.同期群分析(Cohort Analysis)
将相同时间段内具有共同行为特征的用户划分为同一个群体,其被称为同期群。“共同行为特征”是指在某个时间段内的行为相似。最常见的是按不同时间的新增用户来划分,然后分析留存率。它可以提供有关商品和客户生命周期的信息。
同期群分析共有三种类型:
- 时间同类:在一段时间内,将客户按购买行为分组。
- 行为同类:按客户购买的产品或服务对客户进行分组。
- 规模同类:指购买公司产品或服务的各种规模的客户。此分类可以基于一段时间内的支出金额。
了解各种同类群体的需求可以帮助公司设计针对特定细分市场的定制服务或产品。
在下面的分析中,将创建“时间同类”群组,并查看在特定同类群组中在一段时间内保持活跃的客户。
cohort_data = df_uk[['InvoiceNo','StockCode','Description','Quantity','InvoiceDate','UnitPrice','CustomerID','Country']]
all_dates = (pd.to_datetime(cohort_data['InvoiceDate'])).apply(lambda x:x.date())
(all_dates.max() - all_dates.min()).days

检查数据的日期范围,开始日期:2010-12-01,结束日期:2011-12-09。
# Start and end dates:
print('Start date: {}'.format(all_dates.min()))
print('End date: {}'.format(all_dates.max()))

cohort_data.head()

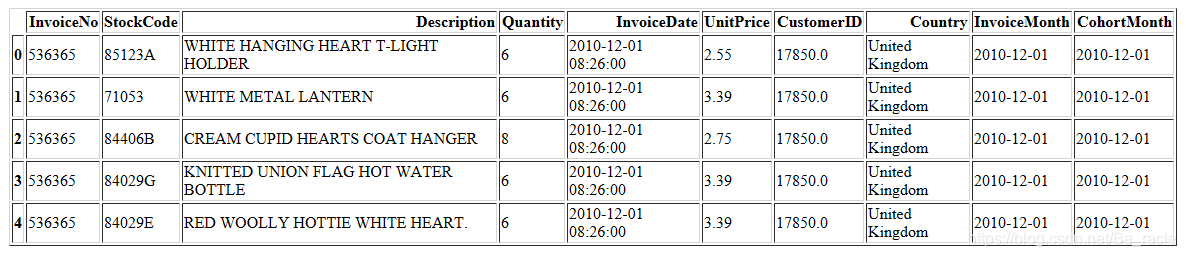
接下来,创建了一个名为InvoiceMonth的列,用来记录每个交易的InvoiceDate的月份时间。然后,提取有关交易第一个月的信息,并按CustomerID分组。
def get_month(x):
return dt.datetime(x.year, x.month, 1)
cohort_data['InvoiceMonth'] = cohort_data['InvoiceDate'].apply(get_month)
grouping = cohort_data.groupby('CustomerID')['InvoiceMonth']
#找到分组的最小值,然后将其赋值给整个组(可广播的标量值),这里表示第一次交易的时间
cohort_data['CohortMonth'] = grouping.transform('min')
cohort_data.head() # 这一步得到的cohort_data在后面还会被用到
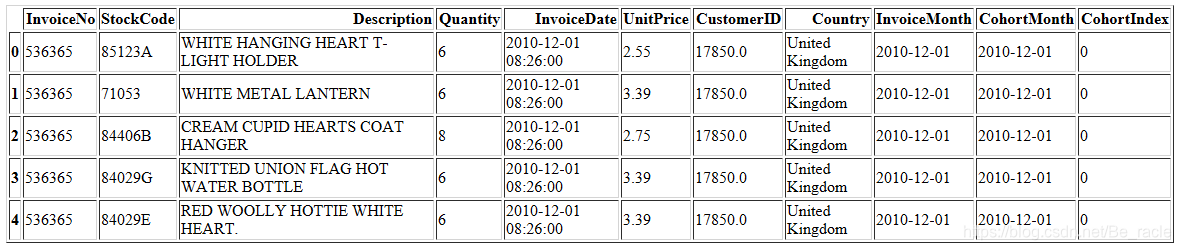
接下来,我们需要找到InvoiceMonth和CohortMonth之间的月份的数差。
def get_date_int(df, column):
year = df[column].dt.year
month = df[column].dt.month
day = df[column].dt.day
return year, month, day
invoice_year, invoice_month, _ = get_date_int(cohort_data, 'InvoiceMonth')
cohort_year, cohort_month, _ = get_date_int(cohort_data, 'CohortMonth')
years_diff = invoice_year - cohort_year
months_diff = invoice_month - cohort_month
cohort_data['CohortIndex'] = years_diff * 12 + months_diff
cohort_data.head()
获得上述信息后,将数据按CohortMonth和CohortIndex分组,并通过应用pd.Series.nunique函数在CustomerID列上进行汇总来获得同类分析矩阵。
grouping = cohort_data.groupby(['CohortMonth', 'CohortIndex'])
cohort_data = grouping['CustomerID'].apply(pd.Series.nunique) # 用于获取唯一值的统计次数
cohort_data = cohort_data.reset_index()
cohort_counts = cohort_data.pivot(index='CohortMonth',columns='CohortIndex',values='CustomerID')
cohort_counts
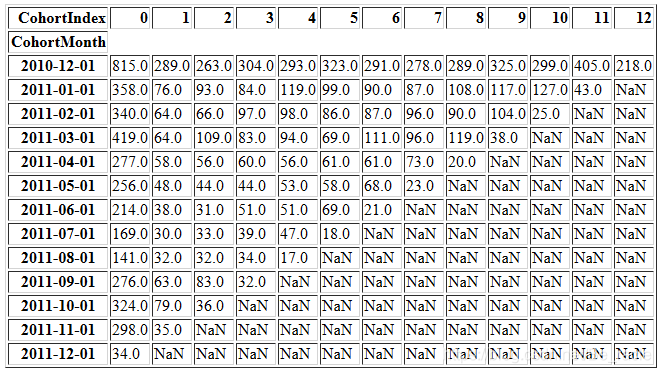
对于CohortMonth 2010-12-01:
- CohortIndex 0,表明有815个客户在2010年12月份进行了首次交易。
- CohortIndex 1,表明815个客户中有289个客户在2010年12月份进行了首次交易,并且在下个月(即2011年1月份)也进行了交易。也就是说,他们保持活跃。
- CohortIndex 2,表明815个客户中有263个客户在2010年12月份进行了首次交易,并且在下下个月(即2011年2月份)也进行了交易。
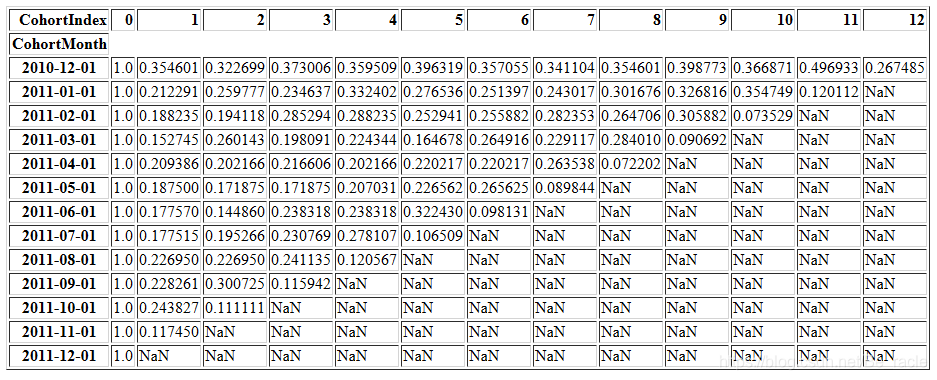
现在计算保留率。它定义为活跃客户占总客户的百分比。由于每个群组中的活跃客户数量对应于CohortIndex 0值,因此我们将数据的第一列作为群组规模。
cohort_sizes = cohort_counts.iloc[:,0]
# Divide all values in the cohort_counts table by cohort_sizes
retention = cohort_counts.divide(cohort_sizes, axis=0)
# Review the retention table
retention.round(3) * 100
retention
我们还可以计算其他指标,例如每个群组的平均数量。(请思考这里的cohort_data到底应该使用前面哪一步得到的cohort_data,否则在Jupyter环境中直接往下运行时会报错的。前文已有提示。)
grouping = cohort_data.groupby(['CohortMonth', 'CohortIndex'])
cohort_data = grouping['Quantity'].mean()
cohort_data = cohort_data.reset_index()
average_quantity = cohort_data.pivot(index='CohortMonth',columns='CohortIndex',values='Quantity')
average_quantity.round(1)
average_quantity
plt.figure(figsize=(10, 8))
plt.title('Retention rates')
sns.heatmap(data = retention,annot = True,fmt = '.0%',vmin = 0.0,vmax = 0.5,cmap = 'BuGn')
plt.show()
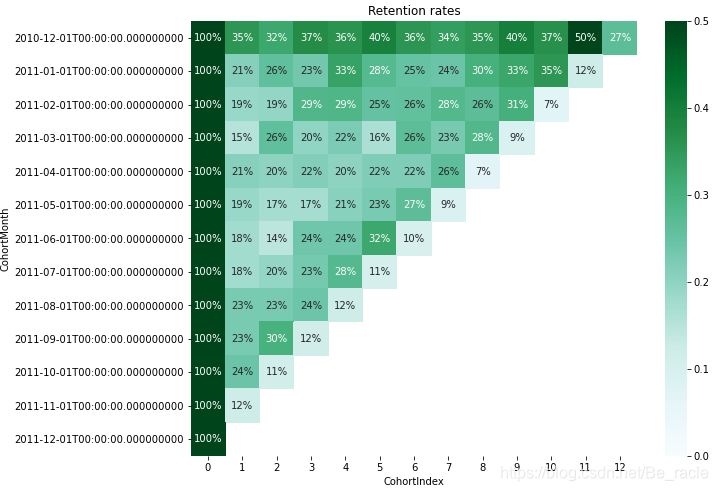
从上面的保留率热图中可以看到CohortMonth 2010-12-01的平均保留率为35%,保留率最高的是11个月后(50%)。对于所有其他同类月份,平均保留率约为18%~25%。只有该百分比的用户在给定的CohortIndex范围内再次进行交易。
通过此分析,公司可以了解并制定策略,以通过提供更具吸引力的折扣或进行更有效的营销来增加客户保留率。
3.利用RFM模型细分客户
RFM分析是一种常用的技术,可根据最近一次交易的最新程度(Recency),最近一年进行的交易次数(Frequency)以及每笔交易的货币价值(Monetary)为每个客户生成并分配分数。
RFM分析有助于回答以下问题:
- 谁是我们最近服务过的客户?
- 他从我们的商店购买了多少次物品?
- 他的交易总价值是多少?
所有这些信息对于了解客户对公司的好坏至关重要。
获取RFM值后,一种常见的做法是在每个指标上创建“四分位数”并分配所需的顺序。例如,假设我们将每个指标分为4个层次。
- 对于新近度指标,最高值4将分配给新近度值最小的客户(因为他们是最近的客户)。
- 对于频率和货币指标,最高的价值4将分别分配给具有前25%频率和货币价值的客户。
在将指标划分为四分位数之后,我们可以将指标记录到单个列中(如字符串“213”的形式),以此为客户创建RFM值类别。根据我们的要求,我们可以将RFM指标划分为更少或更多的层次。
首先,我们需要创建一个列来获取每笔交易的总额。这可以通过将单价(UnitValue)乘以数量(Quantity)来完成。我们记为TotalSum,并在此列上调用describe()函数。
cohort_data['TotalSum'] = cohort_data['Quantity']*cohort_data['UnitPrice']
cohort_data.head()

cohort_data[['TotalSum']].describe()
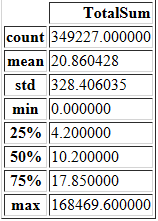
据此,我们大致知道了“消费金额”在数据中是如何划分的不同层次。我们可以看到平均值为20.86,标准差为328.4,最大值为168469。
cohort_data[cohort_data['TotalSum']> 17.850000].sort_values('TotalSum',ascending=False)
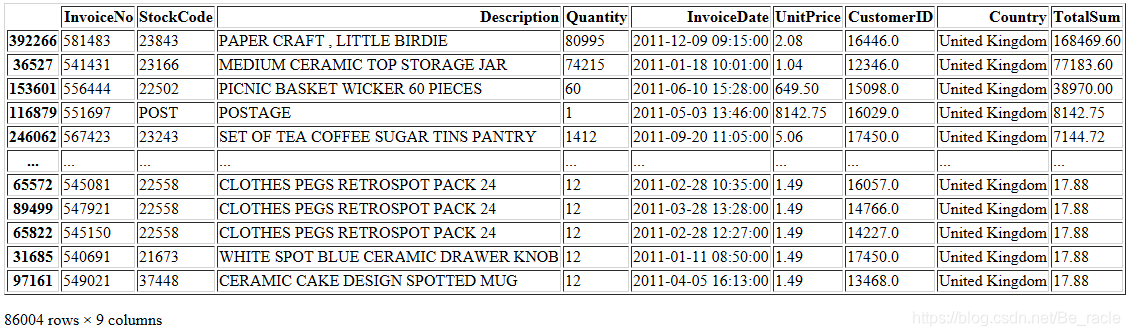
找到最大日期,并获取最大日期之前一年的数据。(再往前的数据此处不再分析了。)
from dateutil.relativedelta import relativedelta
start_date = all_dates.max()-relativedelta(months=12,days=-1)
print('Start date: {}'.format(start_date))
print('End date: {}'.format(all_dates.max()))

data_rfm = cohort_data[cohort_data['InvoiceDate'] >= pd.to_datetime(start_date)]
data_rfm.reset_index(drop=True,inplace=True)
data_rfm.head()

对于RFM分析,我们需要定义一个snapshot_date。在这里,我将snapshot_date定义为数据中的最高日期+1,即2011-12-10。(这样避免了“新近度”为0的情况)
snapshot_date = max(data_rfm.InvoiceDate) + dt.timedelta(days=1)
print('Snapshot date: {}'.format(snapshot_date.date()))

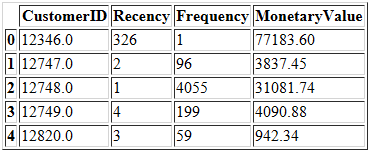
我们将数据日期限制为一年,这样新近度最大值也就限制为365。接下来在客户级别汇总数据并计算每个客户的RFM指标。
# Aggregate data on a customer level
data = data_rfm.groupby(['CustomerID'],as_index=False).agg({
'InvoiceDate': lambda x: (snapshot_date - x.max()).days,
'InvoiceNo': 'count',
'TotalSum': 'sum'}).rename(columns = {
'InvoiceDate': 'Recency',
'InvoiceNo': 'Frequency',
'TotalSum': 'MonetaryValue'})
# Check the first rows
data.head()
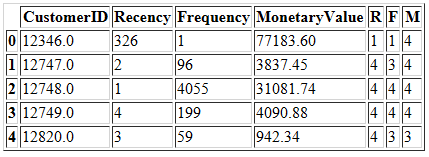
下一步,我们在此数据上创建四分位数,然后将这些分数记录到RFM_Segment列中。RFM_Score是通过将RFM四分位数指标相加得出的。
r_labels = range(4, 0, -1)
r_quartiles = pd.qcut(data['Recency'], 4, labels = r_labels)
data = data.assign(R = r_quartiles.values)
f_labels = range(1,5)
f_quartiles = pd.qcut(data['Frequency'], 4, labels = f_labels)
data = data.assign(F = f_quartiles.values)
m_labels = range(1,5)
m_quartiles = pd.qcut(data['MonetaryValue'], 4, labels = m_labels)
data = data.assign(M = m_quartiles.values)
data.head()
def join_rfm(x):
return str(int(x['R'])) + str(int(x['F'])) + str(int(x['M']))
data['RFM_Segment'] = data.apply(join_rfm, axis=1)
data['RFM_Score'] = data[['R','F','M']].sum(axis=1)
data.head()
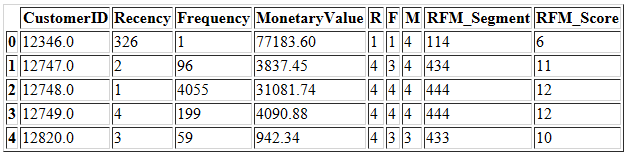
RFM_Score值的范围是3(1 + 1 + 1)到12(4 + 4 + 4)。因此,我们可以将RFM分数分组,并检查与每个分数相对应的新近度,频率和货币平均值。
data.groupby('RFM_Score').agg({
'Recency': 'mean',
'Frequency': 'mean',
'MonetaryValue': ['mean', 'count'] }).round(1)
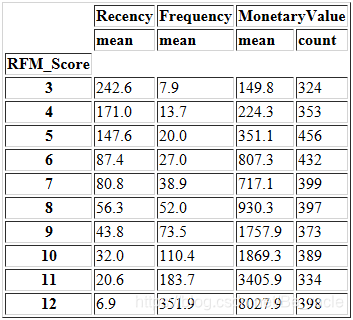
正如前文所说,RFM分数最低的客户具有最高的新近度值,最低的频率和货币价值。
最后,我们可以在数据中手动创建类别,在RFM_Score=3~12的得分范围内创建细分:
- RFM_Score ≥ 9的客户可以置于“Top”类别中;
- 5 ≤ RFM_Score<9之间的客户可以放在“Middle”类别中;
- 剩下的属于“Low”类别。
def create_segment(df):
if df['RFM_Score'] >= 9:
return 'Top'
elif (df['RFM_Score'] >= 5) and (df['RFM_Score'] < 9):
return 'Middle'
else:
return 'Low'
data['General_Segment'] = data.apply(create_segment, axis=1)
data.groupby('General_Segment').agg({
'Recency': 'mean',
'Frequency': 'mean',
'MonetaryValue': ['mean', 'count']}).round(1)
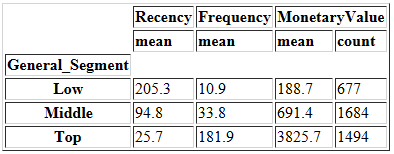
我们可以手动地创建这种细分逻辑,但是,如果我们想在RFM模型上找到合适的细分,也可以使用K-means等聚类算法。
4.利用K-Means细分模型
K-Means是一种聚类算法,常用于无监督学习任务。但是,该算法是有运用前提的,它要求数据满足一些假设条件。因此,我们需要对数据进行预处理,以使其能够满足算法的关键假设:
- 变量应对称分布
- 变量应具有相似的平均值
- 变量应具有相似的标准差值
现在通过使用seaborn绘出最近度、频率和货币价值的直方图来检查第一个假设:
# Checking the distribution of Recency, Frequency and MonetaryValue variables.
plt.figure(figsize=(12,10))
# Plot distribution of var1
plt.subplot(3, 1, 1); sns.distplot(data['Recency'])
# Plot distribution of var2
plt.subplot(3, 1, 2); sns.distplot(data['Frequency'])
# Plot distribution of var3
plt.subplot(3, 1, 3); sns.distplot(data['MonetaryValue'])
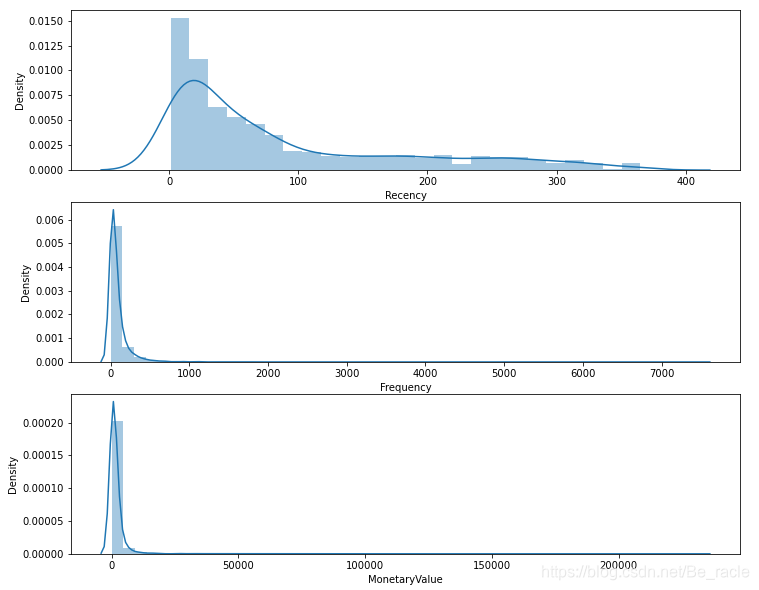
从上图可以看出,R、F、M三个变量都不满足对称分布,它们都向右倾斜。要想消除偏斜,可以尝试一些转换方法。
我这里使用对数转换。由于对数转换不能有负值,因此,如果存在负值,我们需要将其删除。这种情况下,一种常见做法是添加一个常数值以获得一个正值,通常将其视为每个观察值变量最小负值的绝对值。但是,在我们的数据中没有负值。
我们通过调用describe()方法检查新近度,频率和货币价值的分布。
# Checking for constant mean and variance.
data[['Recency','Frequency','MonetaryValue']].describe()
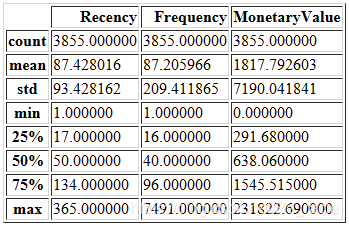
从上面的描述中,我们可以看到特定客户ID的最小MonetaryValue为0。这类事务没有任何意义,需要将其删除。
data[data['MonetaryValue'] == 0]

data = data[data['MonetaryValue'] > 0]
data.reset_index(drop=True,inplace=True)
raw_data = data[['Recency','Frequency','MonetaryValue']]
该客户已从数据中删除。
但是,到此为止,我们还没有获得恒定的均值和标准差。所以,我们还需要对数据进行标准化。首先将对数转换应用于数据,然后通过sklearn库中的StandardScaler()方法进行标准化。
# Unskew the data
data_log = np.log(raw_data)
# Initialize a standard scaler and fit it
scaler = StandardScaler()
scaler.fit(data_log)
# Scale and center the data
data_normalized = scaler.transform(data_log)
# Create a pandas DataFrame
data_norm = pd.DataFrame(data=data_log, index=raw_data.index, columns=raw_data.columns)
data_norm.head()
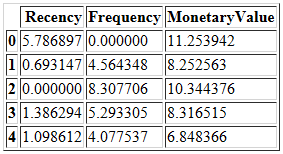
我们获得了预处理后的数据。现在再次检查RFM变量的分布是否呈现对称分布。
plt.figure(figsize=(12,10))
# Plot recency distribution
plt.subplot(3, 1, 1); sns.distplot(data_norm['Recency'])
# Plot frequency distribution
plt.subplot(3, 1, 2); sns.distplot(data_norm['Frequency'])
# Plot monetary value distribution
plt.subplot(3, 1, 3); sns.distplot(data_norm['MonetaryValue'])
# Show the plot
plt.show()
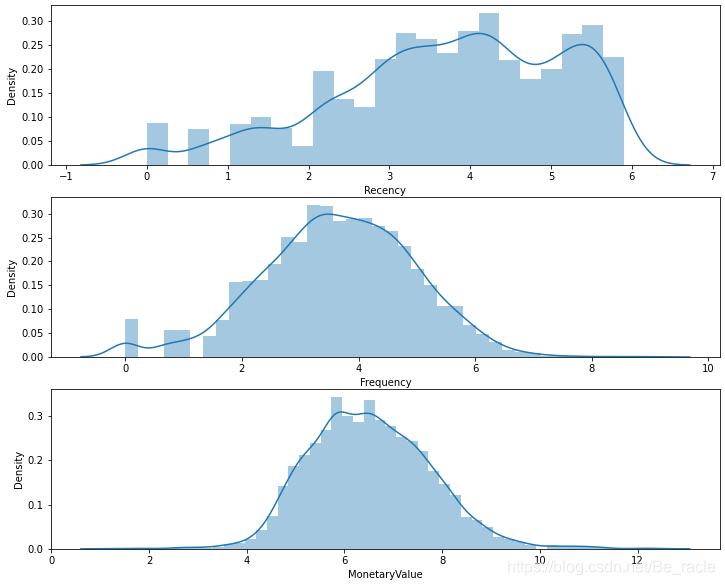
接下来,我们将基于规范化的RFM数据构建多个聚类,并使用肘部法则(elbow method)在我们的数据中找出最佳聚类数目。
from sklearn.cluster import KMeans
sse = {
}
# Fit KMeans and calculate SSE for each k
for k in range(1, 21):
# Initialize KMeans with k clusters
kmeans = KMeans(n_clusters=k, random_state=1)
# Fit KMeans on the normalized dataset
kmeans.fit(data_norm)
# Assign sum of squared distances to k element of dictionary
sse[k] = kmeans.inertia_
plt.figure(figsize=(12,8))
plt.title('The Elbow Method')
plt.xlabel('k');
plt.ylabel('Sum of squared errors')
sns.pointplot(x=list(sse.keys()), y=list(sse.values()))
plt.show()
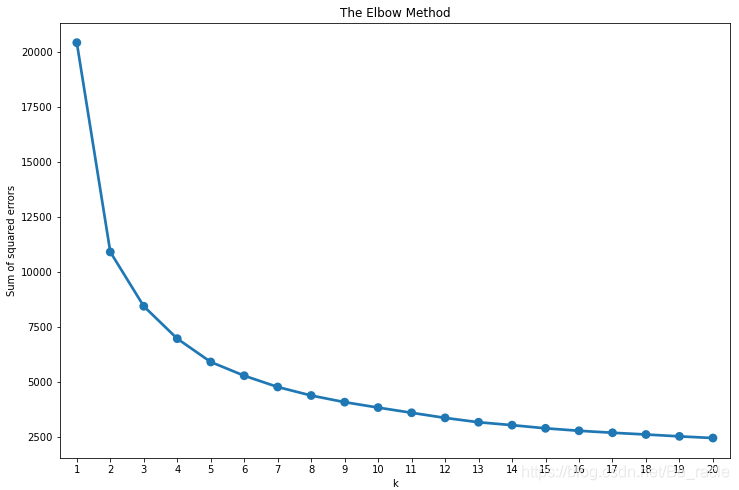
从上面的图中可以看出,最佳的聚类数是3或4。
先看一下聚类数为3时的情况。
kmeans = KMeans(n_clusters=3, random_state=1)
# Compute k-means clustering on pre-processed data
kmeans.fit(data_norm)
# Extract cluster labels from labels_ attribute
cluster_labels = kmeans.labels_
# Create a cluster label column in the original DataFrame
data_norm_k3 = data_norm.assign(Cluster = cluster_labels)
data_k3 = raw_data.assign(Cluster = cluster_labels)
# Calculate average RFM values and size for each cluster
summary_k3 = data_k3.groupby(['Cluster']).agg({
'Recency': 'mean',
'Frequency': 'mean',
'MonetaryValue': ['mean', 'count'],}).round(0)
summary_k3
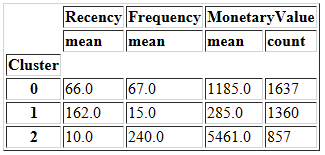
再看一下聚类数为4时的情况。
kmeans = KMeans(n_clusters=4, random_state=1)
# Compute k-means clustering on pre-processed data
kmeans.fit(data_norm)
# Extract cluster labels from labels_ attribute
cluster_labels = kmeans.labels_
#Create a cluster label column in the original DataFrame
data_norm_k4 = data_norm.assign(Cluster = cluster_labels)
data_k4 = raw_data.assign(Cluster = cluster_labels)
# Calculate average RFM values and size for each cluster
summary_k4 = data_k4.groupby(['Cluster']).agg({
'Recency': 'mean',
'Frequency': 'mean',
'MonetaryValue': ['mean', 'count'],}).round(0)
summary_k4
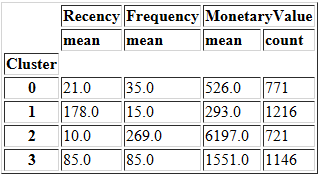
看一下二者的对比情况。
display(summary_k3)
display(summary_k4)
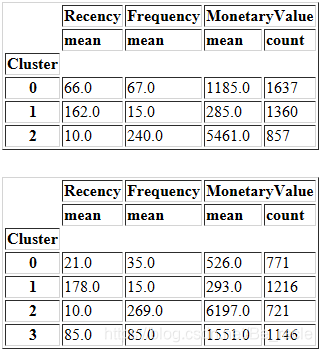
从上表中,我们可以比较3个和4个群集数据的新近度、频率和货币度量的平均值的分布。似乎我们使用k = 4得到了更详细的客户群分布。但是,这表现地并不直观。
比较聚类划分的另一种常用方法是Snakeplots。它通常用于市场研究中以了解客户的看法。
我们下面用聚类数为4时的数据构建一个Snake plot。
data_norm_k4.index = data['CustomerID'].astype(int)
data_norm_k4.head()
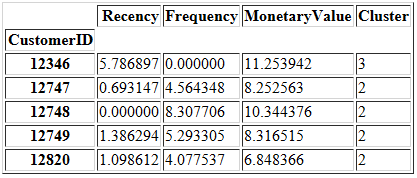
在构建Snake plot之前,我们需要对数据进行融合,以便将RFM值和度量标准名称分别存储在1列中。
# Melt the data into along format so RFM values and metric names are stored in 1 column each
# melt将多列数据进行融合
data_melt = pd.melt(data_norm_k4.reset_index(), #要处理的数据集
id_vars=['CustomerID', 'Cluster'], #不需要被转换的列名
value_vars=['Frequency', 'MonetaryValue','Recency'], #需要转换的列名
var_name='Attribute', #自定义设置对应的列名
value_name='Value') #自定义设置对应的列名
data_melt
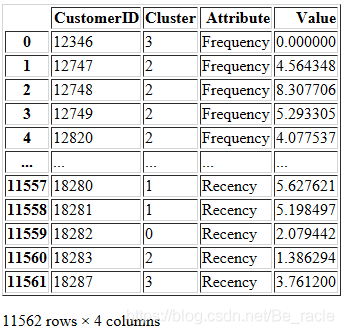
plt.title('Snake plot of standardized variables')
sns.lineplot(x="Attribute", y="Value", hue='Cluster', data=data_melt)
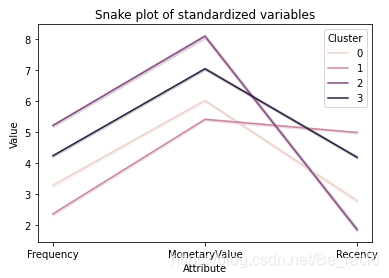
从上图中可以看到四个集群中新近度、频率和货币度量值的分布。四个集群似乎彼此分离,这表明集群之间存在良好的异构混合。
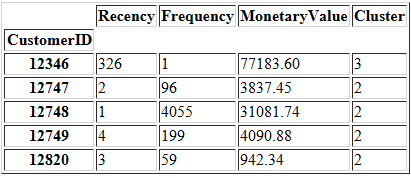
将CustomerID作为data_k4的索引。至此,我们能够清晰地看到每一位客户都属于一个对应的细分集群。
data_k4.index = data['CustomerID'].astype(int)
data_k4.head()
将CustomerID作为raw_data的索引。
raw_data.index = data['CustomerID'].astype(int)
raw_data.head()
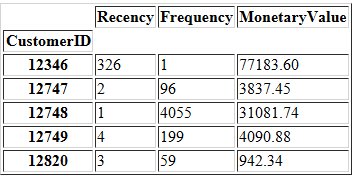
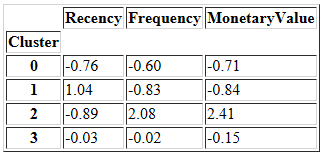
我们还可以通过下面的操作来理解数据段的相对重要性。
- 计算每个集群的平均值
- 计算所有客户的平均值
- 通过将它们相除,再减1来计算重要性分数(确保当聚类平均值等于总体平均值时返回0)
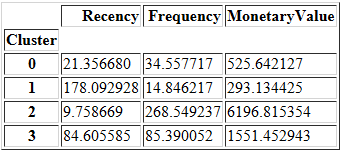
计算每个集群的平均值。
cluster_avg = data_k4.groupby(['Cluster']).mean()
cluster_avg
计算总体的平均值。
population_avg = raw_data.mean()
population_avg

relative_imp = cluster_avg / population_avg - 1
relative_imp.round(2)
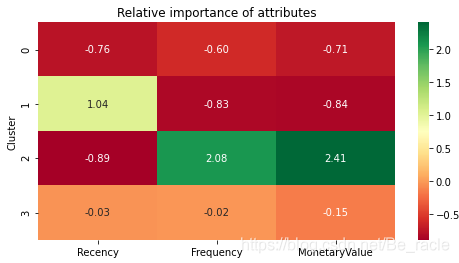
绘制热图。
# Plot heatmap
plt.figure(figsize=(8, 4))
plt.title('Relative importance of attributes')
sns.heatmap(data=relative_imp, annot=True, fmt='.2f', cmap='RdYlGn')
plt.show()
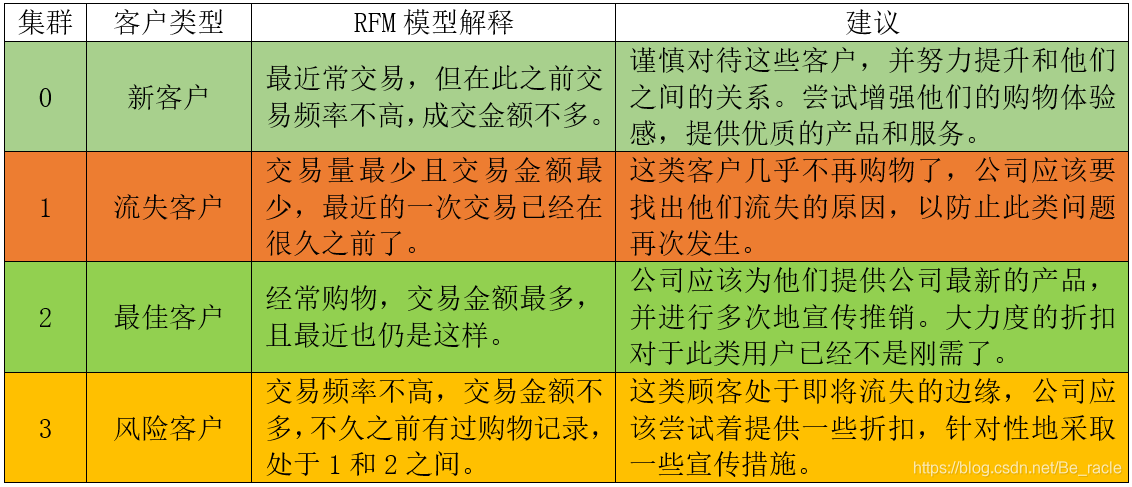
5.结论
智能推荐
Eclipse中配置WebMagic(已配置好Maven)_使用eclipse搭建webmagic工程-程序员宅基地
文章浏览阅读364次。1.WebMagicWebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。2.在Eclipse中配置WebMagic1.首先需要下载WebMagic的压缩包官网地址为:WebMagic官网最新版本为:WebMagic-0.7.3,找到对应版本,打开下载界面,注意,下载要选择Source code(zip)版本,随便下载到哪里都可以;2.下载好的压缩包需要解压,此时解压到的位置即为后续新建的Eclipse的project位置,比如我的Ecli_使用eclipse搭建webmagic工程
linux启动mysql_linux如何启动mysql服务_linux启动mysql服务命令是什么-系统城-程序员宅基地
文章浏览阅读1.9k次。mysql数据库是一种开放源代码的关系型数据库管理系统,有很多朋友都在使用。一些在linux系统上安装了mysql数据库的朋友,却不知道该如何对mysql数据库进行配置。那么linux该如何启动mysql服务呢?接下来小编就给大家带来linux启动mysql服务的命令教程。具体步骤如下:1、首先,我们需要修改mysql的配置文件,一般文件存放在/etc下面,文件名为my.cnf。2、对于mysql..._linux中 mysql 启动服务命令
php实现在线oj,详解OJ(Online Judge)中PHP代码的提交方法及要点-程序员宅基地
文章浏览阅读537次。详解OJ(Online Judge)中PHP代码的提交方法及要点Introduction of How to submit PHP code to Online Judge SystemsIntroduction of How to commit submission in PHP to Online Judge Systems在目前常用的在线oj中,codeforces、spoj、uva、zoj..._while(fscanf(stdin, "%d %d", $a, $b) == 2)
java快捷键调字体_设置MyEclipse编码、补全快捷键、字体大小-程序员宅基地
文章浏览阅读534次。一、设置MyEclipse编码(1)修改工作空间的编码方式:Window-->Preferences-->General-->Workspace-->Text file encoding(2)修改一类文件的编码方式:Window-->Preferences-->General-->content Types-->修改default Encoding(..._java修改快捷缩写内容
解析蓝牙原理_蓝牙原理图详解-程序员宅基地
文章浏览阅读1.4w次,点赞19次,收藏76次。1.前言市面上关于Android的技术书籍很多,几乎每本书也都会涉及到蓝牙开发,但均是上层应用级别的,而且篇幅也普遍短小。对于手机行业的开发者,要进行蓝牙模块的维护,就必须从Android系统底层,至少框架层开始,了解蓝牙的结构和代码实现原理。这方面的文档、网上的各个论坛的相关资料却少之又少。分析原因,大概因为虽然蓝牙协议是完整的,但是并没有具体的实现。蓝牙芯片公司只负责提供最底层的API_蓝牙原理图详解
从未在一起更让人遗憾_“从未在一起和最终没有在一起哪个更遗憾”-程序员宅基地
文章浏览阅读7.7k次。图/源于网络文/曲尚菇凉1.今天早上出门去逛街,在那家冰雪融城店里等待冰淇淋的时候,听到旁边两个女生在讨论很久之前的一期《奇葩说》。那期节目主持人给的辩论题是“从未在一起和最终没有在一起哪个更遗憾”,旁边其中一个女生说,她记得当时印象最深的是有个女孩子说了这样一句话。她说:“如果我喜欢一个人呢,我就从第一眼到最后一眼,把这个人爱够,把我的感觉用光,我只希望那些年让我成长的人是他,之后的那些年他喝过..._从未在一起更遗憾
随便推点
Spring Cloud Alibaba 介绍_sprngcloud alba-程序员宅基地
文章浏览阅读175次。Spring Cloud Alibaba 介绍Sping体系Spring 以 Bean(对象) 为中心,提供 IOC、AOP 等功能。Spring Boot 以 Application(应用) 为中心,提供自动配置、监控等功能。Spring Cloud 以 Service(服务) 为中心,提供服务的注册与发现、服务的调用与负载均衡等功能。Sping Cloud介绍官方介绍 Tools for building common patterns in distributed systems_sprngcloud alba
测试 数据类型的一些测试点和经验_基础字段的测试点-程序员宅基地
文章浏览阅读3.2k次,点赞4次,收藏21次。我这里是根据之前在测试数据类项目过程中的一些总结经验和掉过个坑,记录一下,可以给其他人做个参考,没什么高深的东西,但是如果不注意这些细节点,后期也许会陷入无尽的扯皮当中。1 需求实现的准确度根据产品需求文档描述发现不明确不详细的或者存在歧义的地方一定要确认,例如数据表中的一些字段,与开发和产品确认一遍,如有第三方相关的,要和第三方确认,数据类项目需要的是细心,哪怕数据库中的一个字段如果没有提前对清楚,后期再重新补充,会投入更大的精力。2 数据的合理性根据业务场景/常识推理,提..._基础字段的测试点
一文看懂:行业分析怎么做?_码工小熊-程序员宅基地
文章浏览阅读491次。大家好,我是爱学习的小xiong熊妹。在工作和面试中,很多小伙伴会遇到“对XX行业进行分析”的要求。一听“行业分析”四个字,好多人会觉得特别高大上,不知道该怎么做。今天给大家一个懒人攻略,小伙伴们可以快速上手哦。一、什么是行业?在做数据分析的时候,“行业”两个字,一般指的是:围绕一个商品,从生产到销售相关的全部企业。以化妆品为例,站在消费者角度,就是简简单单的从商店里买了一支唇膏回去。可站在行业角度,从生产到销售,有相当多的企业在参与工作(如下图)在行业中,每个企业常常扮._码工小熊
LLaMA 简介:一个基础的、650 亿参数的大型语言模型_llma-程序员宅基地
文章浏览阅读1.6w次,点赞2次,收藏2次。还需要做更多的研究来解决大型语言模型中的偏见、有毒评论和幻觉的风险。我们在数万亿个令牌上训练我们的模型,并表明可以仅使用公开可用的数据集来训练最先进的模型,而无需诉诸专有和不可访问的数据集。在大型语言模型空间中训练像 LLaMA 这样的小型基础模型是可取的,因为它需要更少的计算能力和资源来测试新方法、验证他人的工作和探索新的用例。作为 Meta 对开放科学承诺的一部分,今天我们公开发布 LLaMA(大型语言模型元 AI),这是一种最先进的基础大型语言模型,旨在帮助研究人员推进他们在 AI 子领域的工作。_llma
强化学习在制造业领域的应用:智能制造的未来-程序员宅基地
文章浏览阅读223次,点赞3次,收藏5次。1.背景介绍制造业是国家经济发展的重要引擎,其产能和质量对于国家经济的稳定和发展具有重要意义。随着工业技术的不断发展,制造业的生产方式也不断发生变化。传统的制造业通常依赖于人工操作和手工艺,这种方式的缺点是低效率、低产量和不稳定的质量。随着信息化、智能化和网络化等新技术的出现,制造业开始向智能制造迈出了第一步。智能制造的核心是通过大数据、人工智能、计算机视觉等技术,实现制造过程的智能化、自动化...
ansible--安装与使用_pip安装ansible-程序员宅基地
文章浏览阅读938次。系列文章目录文章目录系列文章目录 前言 一、ansible是什么? 二、使用步骤 1.引入库 2.读入数据 总结前言菜鸟一只,刚开始使用,仅作以后参考使用。边学习,边记录,介绍一下最基础的使用,可能会有理解不到位的地方,可以共同交流,废话不多说,走起。一、ansible 简介?ansible是自动化运维工具的一种,基于Python开发,可以实现批量系统配置,批量程序部署,批量运行命令,ansible是基于模块工作的,它本身没有批量部署的能力,真正.._pip安装ansible