Java高级特性之XML_java xml示“收藏信息.xml”文件中收藏的手机品牌和型号-程序员宅基地

(题图:wikipedia.org)
- XML语言简介
- XML文档编写规范
- 什么是DOM解析XML
- DOM解析XML的方法
- DOM4J解析XML的方法
- XML与操作系统、编程语言的开发平台无关;
- 实现不同系统之间的数据交换
- 数据交互
- 配置应用程序和网站
- Ajax基石
<!--声明-->
<?xml version="1.0" encoding="UTF-8"?>
<!--文档元素描述信息(文档结构)-->
<books>
<!-- 图书信息-->
<book id="bk101">
<author>王珊</author>
<title>.NET高级编程</title>
<description>包含C#框架和网络编程等</description>
</book>
<book id="bk102">
<author>李明明</author>
<title>XML基础编程</title>
<description>包含XML基础概念和基本作用</description>
</book>
</books>- 属性值用双引号包裹
- 一个元素可以有多个属性
- 属性值中不能直接包含<、 “、& (不建议:‘、>)
- 所有XML元素都必须有结束标签
- XML标签对大小写敏感
- XML必须正确的嵌套
- 同级标签以缩进对齐
- 元素名称可以包含字母、数字或其他的字符
- 元素名称不能以数字或者标点符号开始
- 元素名称中不能含空格
| 符号 | 转义符 | 英文全称 |
| < | < | less than |
| > | > | greater than |
| " | " | quot |
| ' | ' | apos |
| & | & | ampersand |
<description>
<![CDATA[讲解了元素<title>以及</title>的使用]]>
</description>xmlns:namespace-prefix="namespaceURI"- prefix是前缀名称,作为命名空间的别名
- xmlns是保留属性
<?xml version= "1.0" encoding="UTF-8"?>
<cameras xmlns:canon="http://www.canon.com" xmlns:nikon="http://www.nikon.com">
<canon:camera prodID= "P663" name="Camera傻瓜相机"/>
<nikon:camera prodID=“K29B3” name=“Camera超级35毫米相机"/>
</cameras><?xml version= "1.0" encoding="UTF-8"?>
<batchCompany xmlns="http://www.FatliTalk.com" xmlns:tea="http://www.tea.org">
<batch-list>
<batch type= "thirdbatch">第三批次</batch>
<batch tea:type="thirdbatch">第三批茶</batch>
<batch>午班批次</batch>
</batch-list>
</batchCompany>- 非验证解析器
- 验证解析器:DTD、Schema
- 拥有正确语法的 XML 被称为"形式良好"的 XML。
- 通过 DTD 验证的XML是"合法"的 XML。
- XML 文档必须有一个根元素
- XML元素都必须有一个关闭标签
- XML 标签对大小写敏感
- XML 元素必须被正确的嵌套
- XML 属性值必须加引号
<?xml version="1.0" encoding="ISO-8859-1"?>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>合法的 XML 文档是"形式良好"的 XML 文档,这也符合文档类型定义(DTD)的规则:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE note SYSTEM "Note.dtd">
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note<!ELEMENT NAME CONTENT><!DOCTYPE note
[
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>W3C 支持一种基于 XML 的 DTD 代替者,它名为 XML Schema:
<xs:element name="note">
<xs:complexType>
<xs:sequence>
<xs:element name="to" type="xs:string"/>
<xs:element name="from" type="xs:string"/>
<xs:element name="heading" type="xs:string"/>
<xs:element name="body" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>- 基于XML文档树结构的解析
- 适用于多次访问的XML文档
- 特点:比较消耗资源
- 基于事件的解析
- 适用于大数据量的XML文档
- 特点:占用资源少,内存消耗小
- 非常优秀的Java XML API
- 性能优异、功能强大
- 开放源代码
- 文档对象模型(Document Object Model)
- DOM把XML文档映射成一个倒挂的树(以根元素为根节点,每个节点都已对象形式存在。通过获取这些对象就能够获取存取XML文档的内容)

| 常用接口 | 常用方法 | 说明 |
| Document:表示整个XML 文档 |
NodeList
getElementsByTagName(String Tag)
|
按文档顺序返回文档中指定标记名称的所有元素集合 |
| Element createElement(String tagName) | 创建指定标记名称的元素 | |
| Node:该文档树中的单个节点 | NodeList getChildNodes() | 获取该元素的所有子节点,返回节点集合 |
| Element:XML 文档中的一个元素 | String getTagName() | 获取元素名称 |
- 创建解析器工厂对象,即DocumentBuilderFactory对象
- 解析器工厂对象创建解析器对象,即DocumentBuilder对象
- 由解析器对象对指定XML文件进行解析,构建相应的DOM树,创建Document对象
- 以Document对象为起点操作DOM树 的节点进行增加、删除、修改、查询等操作
<?xml version="1.0" encoding="GB2312"?>
<PhoneInfo>
<Brand name="华为">
<Type name="U8650"/>
</Brand>
<Brand name="苹果">
<Type name="iPhone4"/>
<Type name="iPhone5"/>
</Brand>
</PhoneInfo>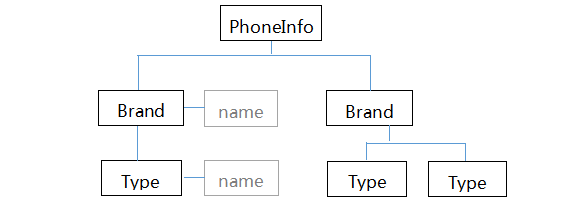
/*关键代码*/
//步骤1:得到DOM解析器的工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//步骤2:从DOM工厂获得DOM解析器
DocumentBuilder db = dbf.newDocumentBuilder();
//步骤3:解析XML文档,得到一个Document对象,即DOM树
Document doc = db.parse("src/收藏信息.xml");
//步骤4:以Document对象为起点操作DOM树 的节点进行增加、删除、修改、查询等操作
//得到所有的Brand节点列表信息
NodeList brandList = doc.getElementsByTagName("Brand");
//循环Brand信息
for(int i = 0;i < brandList.getLength();i++){
//获取第i个Brand元素信息
Node brand = brandList.item(i);
//获取第i个Brand元素的name属性的值
Element element = (Element) brand;
String attrValue = element.getAttribute("name");
//获取第i个Brand元素的所有子元素的name属性值
NodeList types = element.getChildNodes();
for(int j = 0;j < types.getLength();j++){
Element typeElement = (Element) types.item(j); //Type节点
String type = typeElement.getAttribute("name"); //获得手机型号
System.out.println("手机:"+attrValue+type);
}
}- getElementByTagName(String name):返回一个NodeList对象,它包含了所有给定标签名称的标签
- getDocumentElement():返回一个代表这个DOM树的根节点的Element对象,也就是代表XML文档根元素的对象
- getLength():返回列表长度
- item(index):返回节点列表中指定索引号的节点(Node对象)
- getChildNodes():包含此节点的所有子节点的NodeList
- getFirstChild():如果节点存在子节点,则返回第一个子节点
- getLastChile():如果节点存在子节点,则返回最后一个子节点
- getNextSibling():返回在DOM树中这个节点的下一个兄弟节点
- getPreviousSibling():返回在DOM树中这个节点的上一个兄弟节点
- getNodeName():返回节点的名称
- getNodeValue():返回节点的值
- getNodeType():返回节点的类型
- getAttribute(String attributeName):返回标签中给定属性名称的属性的值
- getElementByTagName(String name):返回具有给定标签名称的所有后代Element的NodeList
public class ParseXMLDemo {
private Document document=null;
public static void main(String[] args) {
ParseXMLDemo pd=new ParseXMLDemo();
pd.getDocument();
pd.showInfo();
// pd.add();
// pd.update();
// pd.savaXML("new.xml");
// pd.delete();
}
public void getDocument(){
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder=factory.newDocumentBuilder();
document=builder.parse("收藏信息.xml");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//获取手机品牌和属性
public void showInfo(){
NodeList brands=document.getElementsByTagName("Brand");
for(int i=0;i<brands.getLength();i++){
Node node=brands.item(i);
Element eleBrand=(Element)node;
System.out.println(eleBrand.getAttribute("name"));
NodeList types=eleBrand.getChildNodes();
for(int j=0;j<types.getLength();j++){
Node typeNode=types.item(j);
if(typeNode.getNodeType()==Node.ELEMENT_NODE){
Element eleType=(Element)typeNode;
System.out.println(eleType.getAttribute("name"));
}
}
}
}
/*保存XML文件
步骤:
·获得TransformerFactory对象
·创建Transformer对象
·创建DOMSource对象
··包含XML信息
·设置输出属性
··编码格式
·创建StreamResult对象
··包含保存文件的信息
·将XML保存到指定文件中
*/
public void savaXML(String path){
TransformerFactory factory=TransformerFactory.newInstance();
factory.setAttribute("indent-number", "4");
try {
Transformer transformer=factory.newTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312");
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
//StreamResult result=new StreamResult(new FileOutputStream(path));
StreamResult result=new StreamResult(new OutputStreamWriter(new FileOutputStream(path), "gb2312"));
DOMSource source=new DOMSource(document);
transformer.transform(source, result);
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*添加DOM节点
演示示例:给手机收藏信息XML中添加新的手机信息:
* 添加新的Brand:三星
* 给Brand节点添加新的子标签Type:Note4
* 将Brand添加到DOM树中
*/
public void add(){
Element element=document.createElement("Brand");
element.setAttribute("name", "三星");
Element ele1=document.createElement("Type");
ele1.setAttribute("name", "Note4");
element.appendChild(ele1);
document.getElementsByTagName("PhoneInfo").item(0).appendChild(element);
this.savaXML("new.xml");
}
/*修改DOM节点:
给所有的Brand标签添加id属性
* 获取Brand标签
* 调用setAttribute()方法添加属性
*/
public void update(){
NodeList brands=document.getElementsByTagName("Brand");
for(int i=0;i<brands.getLength();i++){
Node brand=brands.item(i);
Element eleBrand=(Element)brand;
eleBrand.setAttribute("id", i+"");
}
this.savaXML("new.xml");
}
/*删除DOM节点:
删除Brand值为“华为”的标签
* getElementsByTagName ()方法获取Brand标签列表
* 获得Brand值为“华为”的标签对象
* 通过getParentNode ()方法获得父节点对象
* 调用父节点的removeChild()方法删除节点
*/
public void delete(){
NodeList brands=document.getElementsByTagName("Brand");
for(int i=0;i<brands.getLength();i++){
Node brand=brands.item(i);
Element eleBrand=(Element)brand;
if(eleBrand.getAttribute("name").equals("华为")){
eleBrand.getParentNode().removeChild(eleBrand);
}
}
this.savaXML("new.xml");
}
}
8.2 DOM4J 解析XML:
- 了解DOM4J相关接口
- 使用DOM4J读取、添加、修改、删除XML数据
- DOM4J是一个易用、开源的库(Java XML API),用于XML、XPath和XSLT。它应用于Java平台,采用了Java集合框架并完全支持DOM、SAX和JAXP。
- DOM4J使用简单。只需要了解基本的XML-DOM模型,就能使用。DOM4J最大的特色是使用大量的接口。
- Attribute:定义 XML 属性
- Branch:为能够包含子节点的节点,如XML元素(Element)和文档(Document)定义了一个公共的行为。
- CDATA:定义了 XML CDATA 区域
- CharacterData:是一个标识接口,标识基于字符的节点,如 CDATA、Comment、和 Text
- Comment:定义了 XML 注释的行为
- Document:定义了 XML 文档
- DocumentType:定义 XML DOCTYPE 声明
- Element:定义 XML 元素
- ElementHandle:定义了 Element 对象的处理器
- ElementPath:被 ElementHandle 使用,用于取得当前正在处理的路径层次信息
- Entity:定义 XML entity
- Node:为所有的 dom4j 中 XML 节点定义了多态行为
- NodeFilter:定义了在 dom4j 节点中产生的一个滤镜或谓词的行为(predicate)
- ProcessingInstruction:定义 XML 处理指令
- Text:定义 XML 文本节点
- Visitor:用于实现 Visitor 模式
- XPath:在分析一个字符串后会提供一个 XPath表达式
public class Dom4j {
public static Document doc;
public static void main(String[] args) {
loadDocument();
// showPhoneInfo();
// saveXML("src/新收藏.xml");
// addNewPhoneInfo();
// updatePhoneInfo();
deleteItem();
showPhoneInfo();
}
public static void loadDocument(){
try{
SAXReader saxReader = new SAXReader();
doc = saxReader.read(new File("src/收藏信息.xml"));
}catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
public static void updatePhoneInfo(){
// 获取XML的根节点
Element root = doc.getRootElement();
int id = 0;
for (Iterator itBrand = root.elementIterator(); itBrand.hasNext();) {
Element brand = (Element) itBrand.next();
id++;
brand.addAttribute("id", id + "");
}
saveXML("src/收藏信息.xml");
}
public static void deleteItem(){
// 获取XML的根节点
Element root = doc.getRootElement();
int id = 0;
for (Iterator itBrand = root.elementIterator(); itBrand.hasNext();) {
Element brand = (Element) itBrand.next();
if (brand.attributeValue("name").equals("华为")) {
brand.getParent().remove(brand);
}
}
// saveXML("src/收藏信息.xml");
}
public static void showPhoneInfo() {
// 获取XML的根节点
Element root = doc.getRootElement();
// 遍历所有的Brand标签
for (Iterator itBrand = root.elementIterator(); itBrand.hasNext();) {
Element brand = (Element) itBrand.next();
// 输出标签的name属性
System.out.println("品牌:" + brand.attributeValue("name"));
// 遍历Type标签
for (Iterator itType = brand.elementIterator(); itType.hasNext();) {
Element type = (Element) itType.next();
// 输出标签的name属性
System.out.println("\t型号:" + type.attributeValue("name"));
}
}
}
public static void saveXML(String path){
try {
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK"); // 指定XML编码
XMLWriter writer;
writer = new XMLWriter(new FileWriter(path), format);
writer.write(doc);
writer.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void addNewPhoneInfo(){
// 获取XML的根节点
Element root = doc.getRootElement();
// 创建Brand标签
Element el = root.addElement("Brand");
// 给Brand标签设置属性
el.addAttribute("name", "三星");
// 创建Type标签
Element typeEl = el.addElement("Type");
// 给Type标签设置属性
typeEl.addAttribute("name", "Note4");
saveXML("src/收藏信息.xml");
}
}SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));Element rootElement = document.getRootElement();Element memberElement = root.element("menber"); //"member"是节点名String text = memberElement.getText();
//也可以:
String text = root.elementText("name"); //取得根元素下的name子节点的文字List nodes = rootElement.elements("member");
for(Iterator it = nodes.iterator(); it.hasNext();){
Element element = (Element) it.next();
//……
}for(Iterator it = root.elementIterator(); it.hasNext();){
Element element = (Element) it.next();
//……
}Element ageElement = newMemberElement.addElement("age");ageElement.setText("18");parentElement.remove(childElement);Element contentElement = infoElement.addElement("content");
contentElement.addCDATA(diary.getContent());
contentElement.fetText(); //特别说明:获取节点的 CDATA 值与获取节点的值是同一个方法
contentElement.clearContent(); //清除节点中的内容,CDATA 亦可Element root = document.getRootElement();
Attribute attribute = root.atttibute("size"); //属性名 nametring text = attribute.getText();
//也可以:
//取得根节点下name子节点的属性 firstName 的值
String text2 = root.element("name").attributeValue("firstName");
Element root = document.getRootElement();
for(Iterator it = root.attributeInterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text = attribute.getText();
System.out.println(text);
}newMemberElement.addAttribute("name","sitinspring"); Attribute attribute = root.attribute("name");
attribute.setText("sitinspring");Attribute attribute = root.attribute("size"); //属性名 name
root.remove(attribute);XMLWriter writer = newXMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK"); //指定 XML 编码
XMLWriter writer = newXMLWriter(new FileWriter("output.xml"),format);
writer.write(document);
writer.close();智能推荐
Eclipse中配置WebMagic(已配置好Maven)_使用eclipse搭建webmagic工程-程序员宅基地
文章浏览阅读364次。1.WebMagicWebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。2.在Eclipse中配置WebMagic1.首先需要下载WebMagic的压缩包官网地址为:WebMagic官网最新版本为:WebMagic-0.7.3,找到对应版本,打开下载界面,注意,下载要选择Source code(zip)版本,随便下载到哪里都可以;2.下载好的压缩包需要解压,此时解压到的位置即为后续新建的Eclipse的project位置,比如我的Ecli_使用eclipse搭建webmagic工程
linux启动mysql_linux如何启动mysql服务_linux启动mysql服务命令是什么-系统城-程序员宅基地
文章浏览阅读1.9k次。mysql数据库是一种开放源代码的关系型数据库管理系统,有很多朋友都在使用。一些在linux系统上安装了mysql数据库的朋友,却不知道该如何对mysql数据库进行配置。那么linux该如何启动mysql服务呢?接下来小编就给大家带来linux启动mysql服务的命令教程。具体步骤如下:1、首先,我们需要修改mysql的配置文件,一般文件存放在/etc下面,文件名为my.cnf。2、对于mysql..._linux中 mysql 启动服务命令
php实现在线oj,详解OJ(Online Judge)中PHP代码的提交方法及要点-程序员宅基地
文章浏览阅读537次。详解OJ(Online Judge)中PHP代码的提交方法及要点Introduction of How to submit PHP code to Online Judge SystemsIntroduction of How to commit submission in PHP to Online Judge Systems在目前常用的在线oj中,codeforces、spoj、uva、zoj..._while(fscanf(stdin, "%d %d", $a, $b) == 2)
java快捷键调字体_设置MyEclipse编码、补全快捷键、字体大小-程序员宅基地
文章浏览阅读534次。一、设置MyEclipse编码(1)修改工作空间的编码方式:Window-->Preferences-->General-->Workspace-->Text file encoding(2)修改一类文件的编码方式:Window-->Preferences-->General-->content Types-->修改default Encoding(..._java修改快捷缩写内容
解析蓝牙原理_蓝牙原理图详解-程序员宅基地
文章浏览阅读1.4w次,点赞19次,收藏76次。1.前言市面上关于Android的技术书籍很多,几乎每本书也都会涉及到蓝牙开发,但均是上层应用级别的,而且篇幅也普遍短小。对于手机行业的开发者,要进行蓝牙模块的维护,就必须从Android系统底层,至少框架层开始,了解蓝牙的结构和代码实现原理。这方面的文档、网上的各个论坛的相关资料却少之又少。分析原因,大概因为虽然蓝牙协议是完整的,但是并没有具体的实现。蓝牙芯片公司只负责提供最底层的API_蓝牙原理图详解
从未在一起更让人遗憾_“从未在一起和最终没有在一起哪个更遗憾”-程序员宅基地
文章浏览阅读7.7k次。图/源于网络文/曲尚菇凉1.今天早上出门去逛街,在那家冰雪融城店里等待冰淇淋的时候,听到旁边两个女生在讨论很久之前的一期《奇葩说》。那期节目主持人给的辩论题是“从未在一起和最终没有在一起哪个更遗憾”,旁边其中一个女生说,她记得当时印象最深的是有个女孩子说了这样一句话。她说:“如果我喜欢一个人呢,我就从第一眼到最后一眼,把这个人爱够,把我的感觉用光,我只希望那些年让我成长的人是他,之后的那些年他喝过..._从未在一起更遗憾
随便推点
Spring Cloud Alibaba 介绍_sprngcloud alba-程序员宅基地
文章浏览阅读175次。Spring Cloud Alibaba 介绍Sping体系Spring 以 Bean(对象) 为中心,提供 IOC、AOP 等功能。Spring Boot 以 Application(应用) 为中心,提供自动配置、监控等功能。Spring Cloud 以 Service(服务) 为中心,提供服务的注册与发现、服务的调用与负载均衡等功能。Sping Cloud介绍官方介绍 Tools for building common patterns in distributed systems_sprngcloud alba
测试 数据类型的一些测试点和经验_基础字段的测试点-程序员宅基地
文章浏览阅读3.2k次,点赞4次,收藏21次。我这里是根据之前在测试数据类项目过程中的一些总结经验和掉过个坑,记录一下,可以给其他人做个参考,没什么高深的东西,但是如果不注意这些细节点,后期也许会陷入无尽的扯皮当中。1 需求实现的准确度根据产品需求文档描述发现不明确不详细的或者存在歧义的地方一定要确认,例如数据表中的一些字段,与开发和产品确认一遍,如有第三方相关的,要和第三方确认,数据类项目需要的是细心,哪怕数据库中的一个字段如果没有提前对清楚,后期再重新补充,会投入更大的精力。2 数据的合理性根据业务场景/常识推理,提..._基础字段的测试点
一文看懂:行业分析怎么做?_码工小熊-程序员宅基地
文章浏览阅读491次。大家好,我是爱学习的小xiong熊妹。在工作和面试中,很多小伙伴会遇到“对XX行业进行分析”的要求。一听“行业分析”四个字,好多人会觉得特别高大上,不知道该怎么做。今天给大家一个懒人攻略,小伙伴们可以快速上手哦。一、什么是行业?在做数据分析的时候,“行业”两个字,一般指的是:围绕一个商品,从生产到销售相关的全部企业。以化妆品为例,站在消费者角度,就是简简单单的从商店里买了一支唇膏回去。可站在行业角度,从生产到销售,有相当多的企业在参与工作(如下图)在行业中,每个企业常常扮._码工小熊
LLaMA 简介:一个基础的、650 亿参数的大型语言模型_llma-程序员宅基地
文章浏览阅读1.6w次,点赞2次,收藏2次。还需要做更多的研究来解决大型语言模型中的偏见、有毒评论和幻觉的风险。我们在数万亿个令牌上训练我们的模型,并表明可以仅使用公开可用的数据集来训练最先进的模型,而无需诉诸专有和不可访问的数据集。在大型语言模型空间中训练像 LLaMA 这样的小型基础模型是可取的,因为它需要更少的计算能力和资源来测试新方法、验证他人的工作和探索新的用例。作为 Meta 对开放科学承诺的一部分,今天我们公开发布 LLaMA(大型语言模型元 AI),这是一种最先进的基础大型语言模型,旨在帮助研究人员推进他们在 AI 子领域的工作。_llma
强化学习在制造业领域的应用:智能制造的未来-程序员宅基地
文章浏览阅读223次,点赞3次,收藏5次。1.背景介绍制造业是国家经济发展的重要引擎,其产能和质量对于国家经济的稳定和发展具有重要意义。随着工业技术的不断发展,制造业的生产方式也不断发生变化。传统的制造业通常依赖于人工操作和手工艺,这种方式的缺点是低效率、低产量和不稳定的质量。随着信息化、智能化和网络化等新技术的出现,制造业开始向智能制造迈出了第一步。智能制造的核心是通过大数据、人工智能、计算机视觉等技术,实现制造过程的智能化、自动化...
ansible--安装与使用_pip安装ansible-程序员宅基地
文章浏览阅读938次。系列文章目录文章目录系列文章目录 前言 一、ansible是什么? 二、使用步骤 1.引入库 2.读入数据 总结前言菜鸟一只,刚开始使用,仅作以后参考使用。边学习,边记录,介绍一下最基础的使用,可能会有理解不到位的地方,可以共同交流,废话不多说,走起。一、ansible 简介?ansible是自动化运维工具的一种,基于Python开发,可以实现批量系统配置,批量程序部署,批量运行命令,ansible是基于模块工作的,它本身没有批量部署的能力,真正.._pip安装ansible